
Исторически сложилось, что поисковые системы использовали упрощенные модели для извлечения сигналов для ранжирования и антиспама. По мере роста трафика и кликстрима стал возможным переход к более реалистичным моделям. Например, на смену модели случайного блуждания PageRank пришли модели учета поведения реальных пользователей ( и аналогичные алгоритмы).
Конечно, этот переход не означает безоговорочного отказа от традиционного PageRank, но означает уменьшение его вклада в расчет релевантности документа в пользу новых возможностей.
Важно, что реалистичные модели обеспечивают не только лучший сигнал в ранжировании, но и позволяют эффективно подавлять спам. Рассмотрим некоторые подходы, опубликованные в статье «», .
Авторы решили две задачи:
- Выявлены поведенческие шаблоны, позволяющие эффективно обнаруживать спам,
- Создана платформа для обнаружения новых способов спама.
Технической базой для эксперимента послужил фрагмент лога поисковой системы за 57 суток (лето 2007 года). Этот массив данных содержал 22.1 миллиона пользовательских сессий и 2,74 миллиарда кликов по 800 миллионам документов.
Шаблоны, хорошо характеризующие спам
Доля seo-трафика на документ
Определим долю seo-трафика (search engine oriented visit, SEOV):
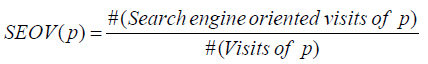
Гипотеза проста: на спамные документы пользователи обычно попадают только через поисковую выдачу. Напротив, на качественные документы обычно существует не seo-трафик. Предполагаем, SEOV для спамных документов будет более высоким. Посмотрим на распределение качественных и спамных документов по интервалам SEOV:
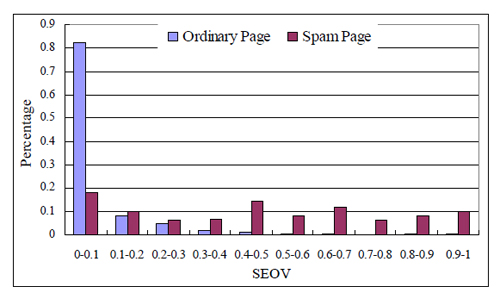
Видно, что 82% хороших документов получили менее 10% трафика из поисковых систем. С другой стороны, для почти 60% спамных документов доля seo-трафика 40% и более. При этом всего 1% качественных документов имеет SEOV более 70%.
Документ как источник трафика
При клике по ссылке и источник, и целевая страница перехода фиксируются в web access log’е. Любой документ может являться как получателем, так и источником трафика. Хотя спамные документы могут содержать большое количество исходящих ссылок, они обычно не порождают трафика на целевые страницы.
Определим долю случаев, в которых документ является источником трафика (source page rate, SP):
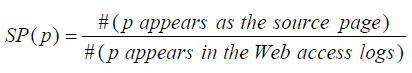
Из распределения документов по приведенному критерию видно, что SP для качественных страниц обычно больше, чем для спамных:
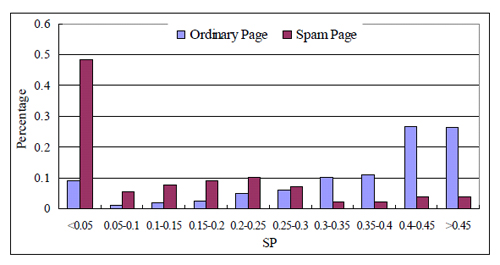
Почти половина спамных документов, присутствующих в training set’е, редко выступают источником трафика (SP
Доля коротких визитов
Очевидно, контент спамных документов не стимулирует пользователей проводить много времени на сайте. Определим долю коротких визитов (short-time navigation rate, SN rate):
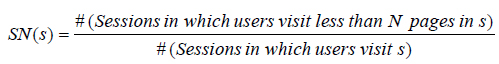
Переменная N может варьироваться, исследователи установили ее равной 3. Физический смысл SN прост — это доля сессий, в которых было просмотрено менее N документов сайта.
Видно, что доля коротких визитов позволяет неплохо решить задачу выявления спама:
Алгоритм обнаружения спама, основанный на анализе особенностей поведения пользователей
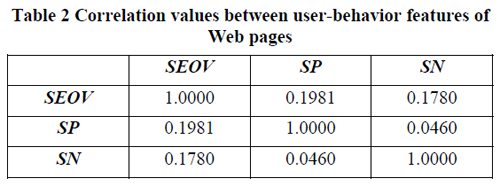
Выявление спама — типичная задача классификации. Исследователи использовали наивный байесовский классификатор и рассмотрели одно- и многофакторную модели. Итоговая функция оценки вероятности документа быть спамным:

Детали реализации доступны в исходной статье.
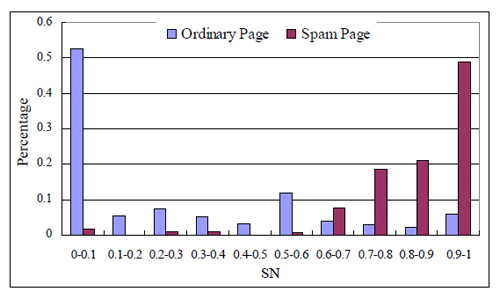
Интересно, что предложенные факторы оказались практически независимы:
По-видимому, это связано с различной природой источников данных.
Алгоритм выявления спама:
- Сбор лога,
- Расчет SEOV и SP для каждого документа,
- Расчет SEOV и SP для каждого сайта (усредняя документные данные п.2),
- Расчет SN для каждого сайта,
- Расчет вероятности документа оказаться спамным.
Результаты
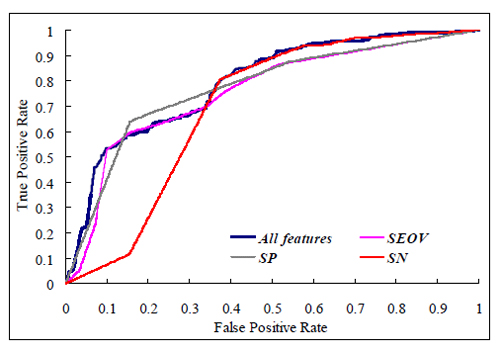
Обучив классификатор, разработчики алгоритма протестировали его на случайной выборке из 1564 сайтов. Асессоры сочли 345 сайтов спамными, 1060 не спамными, 159 — затруднились оценить. Построенная ROC иллюстрирует, что SP и SEOV позволяют эффективнее обнаружить спам, чем SN:
Интересна проблема скорости реакции на появление спама. Традиционно на выявление спама требуется время. Это хорошо видно на следующей кривой:
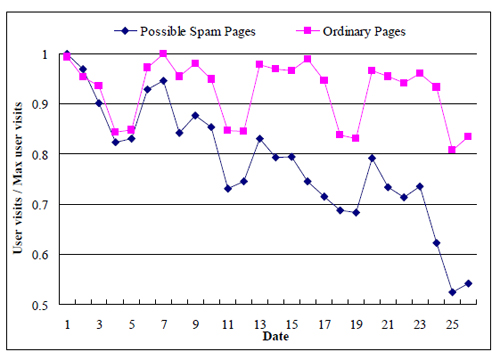
Предложенный авторами метод позволяет ускорить обнаружение спама.
Практические рекомендации
Чтобы снизить вероятность разметки сайта как спамного, нужно:
- Думать о счастье пользователя:
- Размещать полезный контент и сервисы
- Ссылаться на авторитетные источники
- Обеспечивать удобную навигацию
- Стремиться получать трафик из различных источников
- Не привлекать плохо конвертирующийся трафик:
- с низкокачественных и/или нетематических ресурсов
- по объявлениям или ссылкам, не релевантным акцептору
Не используйте спам, привлекайте целевую аудиторию, цените время ваших пользователей. Удачи!

 Теги:
Теги:
