
Все мы давно знаем, что дублированный контент — это зло, с которым надо беспощадно бороться. Специалисты, которые работают в отрасли поисковой оптимизации не первый год, прекрасно знают, как избежать проблем, связанных с появлением дублированного контента на сайте. Новички же могут забывать о некоторых нюансах, которые ведут к созданию дублей страниц. В особой зоне риска находятся интернет-магазины. Из-за огромного количества страниц, структуры сайта онлайн-торговцев подстерегает вероятность появления дублированного контента. Представляем вашему вниманию 9 возможных причин на сайтах интернет-магазинов и советы по их устранению.
- Многоаспектная навигация
Создание дублированного контента из-за многоаспектной навигации — очень распространенная проблема для сайтов электронной коммерции. Доходит до того, что одна страница одного и того же товара может иметь свыше 100 вариаций URL из-за многочисленных комбинаций с применением параметров выбора продукта.

Страница без применения фильтрации по категориям.
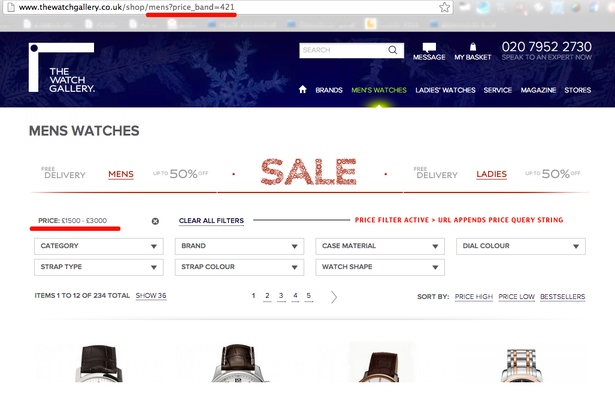
Та же самая страница с применением фильтров.
Приведенный пример показывает, как запрос добавляется в URL при отображении уточненных результатов. Однако контент на странице остается тем же самым.
Решение проблемы:
Существует несколько способов предотвратить индексацию страниц, появившихся в результате многоаспектной навигации.
- мета-тег robots
< meta name="robots" content="noindex,follow«>
Атрибут noindex сообщает поисковым системам, что страницу не следует индексировать, follow — продолжать учитывать ссылки.
- настройка параметров в «Инструментах для Вебмастеров» Google
«Инструменты для Вебмастеров» можно использовать для решения проблем создания динамических страниц. Например, запретить индексировать поисковику URL таких страниц.

- тег Canonical
Прописав тег rel="canonical«, вы можете сообщить поисковым системам, что определенные URL являются разновидностью или дублированной версией другого URL. Есть случаи, когда поисковые системы игнорируют канонические теги и продолжают индексировать страницы. Поэтому некоторые специалисты советуют использовать этот способ совместно с мета-тегом robots.
- Страница заказа товара
Выбирать товары для заказа в каталоге — удобно для пользователей. Но для владельцев интернет-магазинов это еще одна головная боль, так как в результате этого могут появляться страницы с дублированным контентом.
Решение проблемы:
Используйте методы, описанные выше.
- Иерархические URL
Несколько лет назад иерархические URL считались лучшим решением для сайтов e-commerce. Но времена меняются, меняется SEO. Сейчас иерархические URL часто могут стать причиной появления страниц с дублированным контентом, показывающих один и тот же товар из одной категории.
Решение проблемы:
Если есть возможность, рекомендуется переписать адреса страниц, убрав фрагменты-узлы, оставив наименование товара. Также можно использовать тег canonical, чтобы передать вес нужной странице и дать понять поисковикам, какая страница — основная.
- Страницы поиска
Страницы поиска по каталогу — другой яркий пример появления дублированного контента, от которых страдают многие онлайн-магазины.
Решение проблемы:
Самый простой способ заблокировать поисковикам доступ к страницам поиска по каталогу — воспользоваться robots.txt.
Чтобы заблокировать страницу вроде этой: /shop/catalogsearch/result/?q=testquery, пропишите строку в robots.txt: Disallow: /shop/catalogsearch/.
Если страницы поиска уже проиндексированы, удалите их из индекса с помощью «Инструментов для Вебмастеров».
- Интернационализация
Все чаще интернет-магазины запускают международные версии сайтов до того, как переведут весь контент. В результате появляется дублированный контент с описанием товаров с небольшими различиями в URL. Это не очень распространенная проблема, но некоторые сайты с ней сталкиваются.
Решение проблемы:
Перевести контент или, если не успеваете это сделать, заблокировать доступ к страницам без контента.
- Пагинация
Пагинация — другая проблема, из-за которой появляется дублированный контент.
Решение проблемы:
Использовать теги rel=next и prev, введенные Google в 2011 г.
- ID-сессии
Сессии ID — одна из наиболее раздражающих вещей, с которыми приходится сталкиваться специалистам SEO, так как в результате может появиться неограниченное количество дублированных страниц.
Решение проблемы:
Лучшее решение — остановить сессию ID при создании. Также можно воспользоваться «Инструментами для Вебмастеров» от Google, чтобы сообщить поисковым системам об игнорировании сессий ID.
- Страницы для печати
На старых сайтах интернет-магазинов есть возможность отображения печатной версии страницы товара, которая показывает тот же самый контент с другим URL.
Решение проблемы:
Применение мета тега robots (noindex, follow) к динамическим страницам или закрытие каталога в robots.txt.
- Страницы отзывов
Отзывы пользователей могут отображаться несколькими способами в зависимости от построения сайта и CMS. На некоторых сайтах есть отзывы на страницах товаров и страницы только с отзывами.

Как видно из примера, страница отзывов содержит тот же самый контент, но с другим URL.
Решение проблемы:
Чтобы избежать индексации этих страниц, воспользуйтесь файлом robots.txt или используйте мета тег robots (если страницы динамические).

 Теги:
Теги:



