
В блоке быстрых ответов поисковик начал отображать контент со сторонних сайтов. Как к этому относиться владельцам ресурсов, теряющим на трафике?
Однажды холодным январским днем Google выкатил изменения, которые могут осуществить революцию в органической выдаче. На данный момент влияние этой технологии на поисковую выдачу ограничено. Может пройти даже несколько лет, прежде чем будет достигнут максимальный эффект. Но уже сейчас понятно, что внесенные изменения послужат базой для развития Графа знаний и станут новой вехой во взаимодействии Google и вебмастеров.
Блок ответов 1.0.
Начнем с начала. Маркетолог Moz Питер Дж. Майерс (Peter J. Meyers) в свое время много писал про систему Google (так называемые «direct answers» или «one-box answers»). Подобные блоки — это ответы на конкретные сиюминутные запросы.
Приведем пример: если мы захотим узнать, в какое время сегодня открыт для посещений Музей Космонавтики в Москве, мы можем спросить поисковик [музей космонавтики часы работы] и получить вот такой ответ:
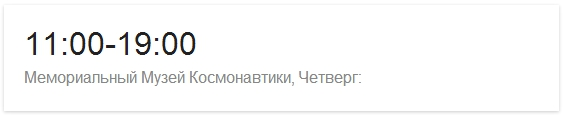
Способность Google понимать запрос значительно улучшилась за последние несколько лет, и вероятно, важную роль в этом занимает алгоритм Hummingbird (Колибри). Например, мы можем получить такой же прямой ответ, задав поисковику запрос [когда открыт музей космонавтики].
Откуда эти данные приходят? Как правило, прямо из Графа знаний, и вы легко можете это обнаружить. Здесь представлена панель Графа знаний для [музей космонавтики]:
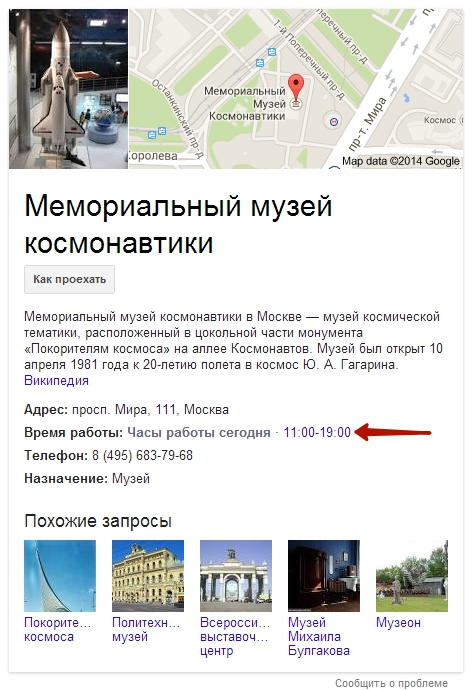
Как видите (красная стрелка), информация для блока ответов берется непосредственно из Графа знаний.
Используя данные из Графов, вы сами можете создавать большое количество примеров. Например, для Останкинской телебашни возьмем свойство «Открытие: 1967 г.» и превратим его в запрос [башня останкино открытие]. Получаем вот такой ответ:
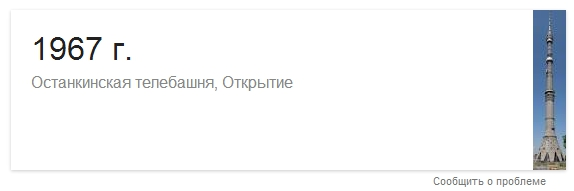
Все данные поступают из очень ограниченного количества источников. Ими могут быть Wikipedia, Google+, . Структура Freebase описана в терминах объектов и свойств (объектно-ориентированно, в отличие от статейно-ориентированной Википедии), что делает ее идеальной для использования в Графе знаний.
Дилемма Google
Но не все так радужно. Основные источники данных для Графа знаний обслуживаются людьми. Интересно, что Google при работе с Графом знаний в 2014 году сталкивается с похожей проблемой, которая ранее привела к созданию поисковых машин. В двух словах: объем информации слишком велик для обработки человеком и растет слишком быстро. «Нельзя просто взять и нанять всех редакторов Википедии». Для того, чтобы Граф знаний был максимально полным, усилий простых редакторов и даже информации из открытых баз данных недостаточно. Google нужен новый источник данных.
Поисковик не может игнорировать данную проблему. В , опубликованном в этом году, Google описывает ситуацию:
Совершенствование баз знаний при помощи технологий веб-поиска
Аннотация: За последние несколько лет огромные объемы мировых знаний накоплены в общедоступных базах данных, таких как Freebase, NELL и YAGO. Несмотря на их, казалось бы, огромные размеры, данные в этих базах далеко не полные. Например, 70% людей, включенных во Freebase, не имеют известного места рождения, а 99% не имеют известной этнической принадлежности. В данной статье мы предлагаем способ использования существующей технологии веб-поиска для целенаправленного заполнения пробелов в подобных базах данных.
Материал направлен на то, чтобы объяснить метод получения недостающих данных, используя существующие поисковые технологии Google. И вот что мы получаем в итоге.
Блок ответов 2.0
К счастью (для них), Google уже имеет один из самых больших источников данных на планете — свой индекс мирового веба. Что если вместо того, чтобы искать ответы в ограниченном наборе энциклопедических источников, Google сможет генерировать ответы, используя данные наших веб-сайтов?
Именно так поиск работает сейчас. Вот что вы можете увидеть в топе органической выдачи по запросу [social security tax rate]*:
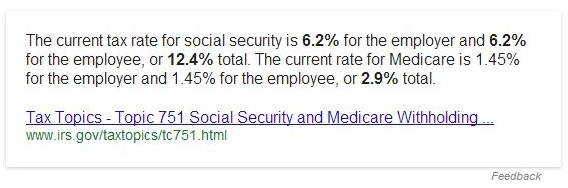
В отличие от ответов, берущихся из Графа знаний, этот новый формат подкачивает информацию непосредственно со сторонних веб-сайтов, отдавая донору ссылку с заголовка страницы. Это дополнительный органический результат, но в выдаче он представляется на первом месте как самый релевантный.
Следующий пример. Расположенный ниже блок в чем-то похож на поисковый сниппет, но появляется только в том случае, когда Google может найти однозначный ответ на стороннем сайте. Посмотрите на блок ответов по запросу [September birthstone]:
* Здесь и далее — примеры из американской выдачи Google . Аналогов в русскоязычном Google пока не найдено.
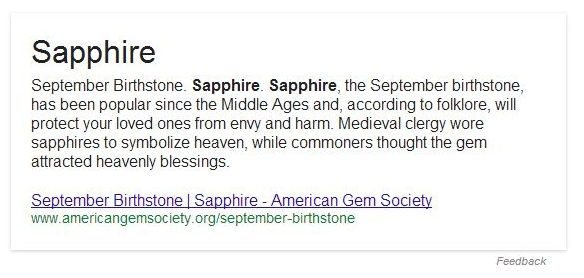
Этот блок включает в себя большой фрагмент текста, но прямой ответ — «Sapphire» — будет подсвечен. Опять же, заголовок страницы-донора и URL будут представлены ниже.
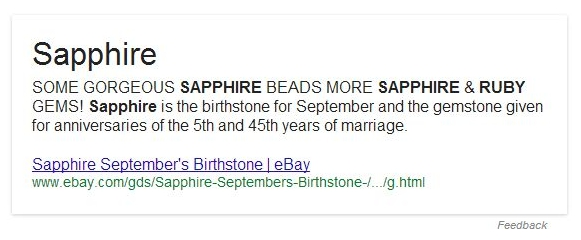
Как мы можем узнать, что при подобной форме ответа информация идет не из стандартного Графа знаний? Можно попробовать вариации запроса — [september’s birthstone], и получить похожий результат:
Вот блок с ответом на более длинную версию запроса [what is september’s birthstone]:
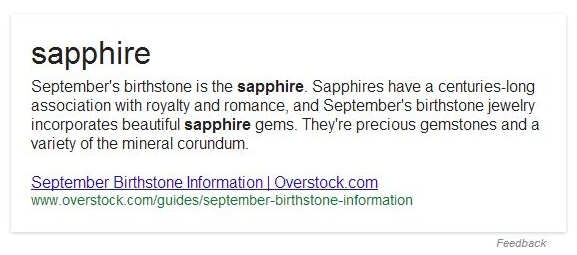
Интересным является тот факт, что короткий ответ («sapphire»), больше не выделяется прописной буквой, потому что именно в таком виде Google нашел его на исходной странице. Очевидно, что эти ответы генерируются на лету.
Новичок № 1
Эти блоки ответов, по существу, новый результат в органике, и нарушают сложившуюся форму представления результатов в поисковом топе. Итак, откуда эти ответы приходят, и как обзавестись чем-то подобным для своего сайта? Данных для точного ответа недостаточно, но страница, с которой поисковик берет информацию, как правило, должна высоко ранжироваться.
В большинстве случаев (опять же, выборка мала), информация приходит от первой позиции в поисковой выдаче. Например, вот блок ответа и первое место в поисковой выдаче по запросу (и вновь зарубежный Google) [marine corps’ birthday]:
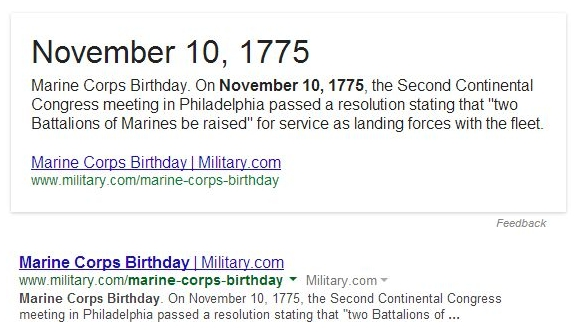
Military.com получает таким образом две первые позиции в поисковом топе. В некоторых случаях информация берется из результата, расположенного на первой странице выдачи, но ниже самого релевантного результата. Вот блок ответа и часть первой страницы для [richest man in the world]:
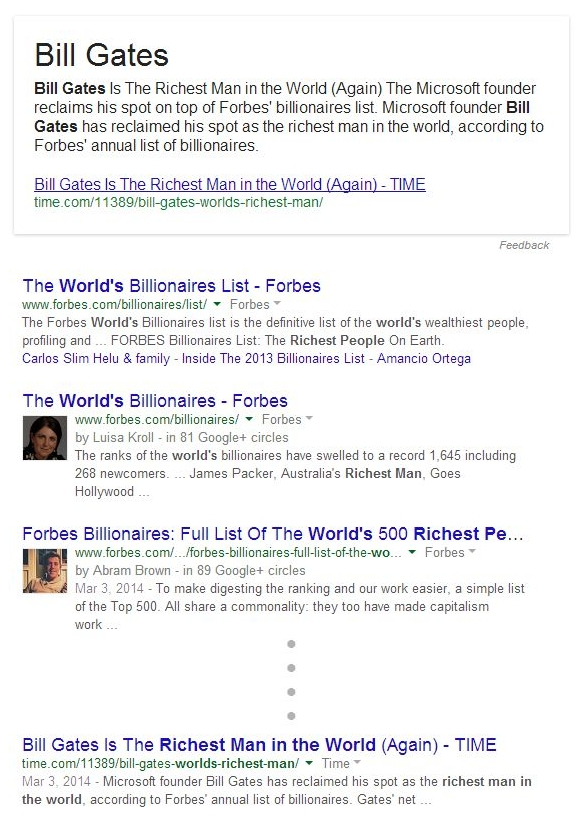
В данном случае Time является источником для блока с быстрым ответом, хотя занимает в органике восьмую позицию, а Forbes, при этом, занимает первые три позиции. Более того, Time в своей статье напрямую ссылается на Forbes в качестве источника, даже в поисковом сниппете. Так почему источником послужила именно страница Time?
Вероятнее всего, все сводится к основным факторам, характеризующим страницу. Основная статья Forbes — тяжелая в плане дизайна (возможности к краулу страницы ограничены), использует «бесконечную» прокрутку. Ни одна из перечисленных страниц Forbes не содержит прямого вхождения «richest man in the world», тем более в контексте имени Билла Гейтса.
Что будет, если изменить запрос так, чтобы он стал более целевым для Forbes, например [world’s richest people]? Вот результат (все запросы вводились в режиме инкогнито, но не исключена какая-то история в рамках поисковой сессии):
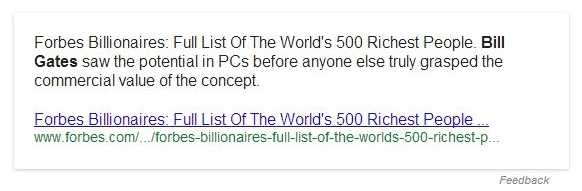
Интересно то, что Google, похоже, знает, что мы хотим увидеть, и подсвечивает «Bill Gates». Но Google не считает результат окончательным и не выводит его в виде быстрого ответа.
Это только начало
Очевидно, Google еще есть над чем работать. Иногда попадаются довольно забавные блоки ответов. Например, для запроса [hair color] выводятся преимущества продукции для волос:
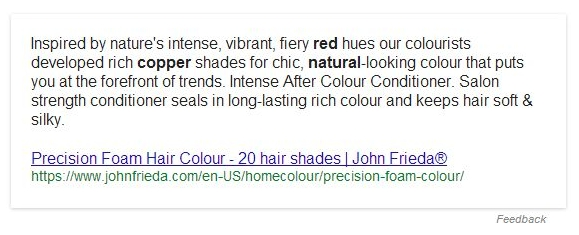
Данный запрос является довольно неоднозначным и вряд ли подходит для получения ответа в подобном новом блоке. Можно ожидать, что Google в ближайшее время потратит немало времени и ресурсов на совершенствование системы.
В то же время, кроме использования этой технологии для составления быстрых ответов, Google использует аналогичные методы для расширения панели Графа знаний. Вот, например, панель Графа знаний по запросу [biology]:
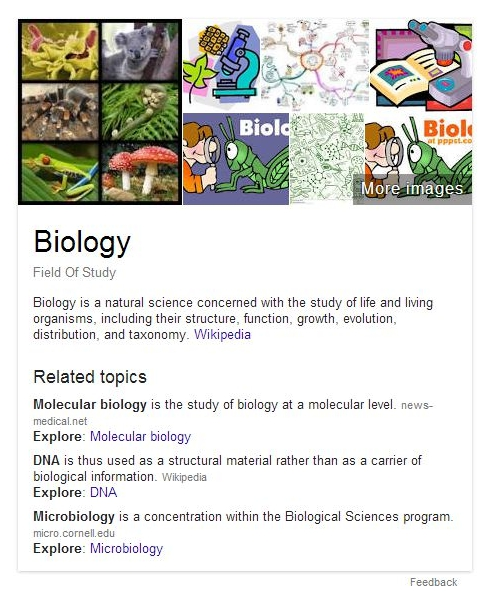
Обратите внимание на раздел «Related topics» («похожие запросы»). В них имеется только один результат, взятый из Википедии. Google создает довольно большой фрагмент в панели, используя данные с сайтов, находящихся в его индексе. Ссылка донору — небольшая, серым шрифтом. Синим выделены ссылки на поиск в Google по соответствующим запросам (исключение сделано для Википедии, ссылка под основным описанием термина).
Изменения неизбежны?
Google необходимо расширять свой Граф знаний, и поисковик не может во всем полагаться на редакторов и базы данных, вроде Википедии. В то время как описанный новый формат может быть удобен для пользователей, происходят изменения в сложившейся схеме взаимодействия между поиском и вебмастером. Всегда существовал своеобразный симбиоз — Google сканировал наши сайты и извлекал информацию, но в ответ посылал трафик. Нам не всегда нравилось, что делал Google, но от конечного результата выигрывали миллионы вебмастеров.
Что может произойти, если пользователь сможет получить быстрый ответ в выдаче, если информация берется с сайтов третьих лиц, и при этом съедается часть органических кликов? Каковы могут быть последствия того, что сторонние данные используются не для привлечения трафика на источник, а исключительно для целей поиска Google? Возможно, сложившийся симбиоз находится под угрозой.
Что можно сделать в будущем, когда эти изменения доберутся до выдачи русскоязычного Google? Вы можете улучшить контент на ваших страницах так, чтобы он отображался в новом блоке ответов, но при этом рискуете не получить часть трафика. Конечно, лучше быть в блоке с ответом вам, чем вашему конкуренту, но вряд ли это идеальный вариант. Единственное, что точно нужно знать — это не только как ранжируются ваши страницы, но и как выглядит поисковая выдача в целом в контексте той отдачи, которую вы получаете от поисковика. В итоге, нам придется решить, стоят ли наши данные того, что мы получаем взамен.
Немного про русскоязычную выдачу Google. Единственная причина, по которой в качестве примеров приводились запросы на английском — это отсутствие известных примеров-запросов на нашем языке. Из того, что видел я — в нашей выдаче Google на данный момент использует только свой Граф знаний, подтягивая данные из Википедии. Из нее берутся данные для панели Графа знаний и блока быстрых ответов (спросите у Google [что такое сапфир]).
В панели знаний не используются данные из источников, отличных от Википедии. Также в выдаче нет блока ответов, формирующегося из данных, полученных с третьих сайтов. Видимо, изменения, проиллюстрированные и описанные выше, не внедрены в русскоязычный сегмент Google. Но эти изменения, как мне кажется, на заставят себя ждать.
Также, полагаю, что поднятая проблематика будет носить особый характер для вебмастеров, работающих в русскоязычном сегменте. И вопрос даже не в том, как наш сегмент Google будет отличаться от западного, а как мы воспринимаем изменения Google. Могу говорить только за себя, но я воспринимаю все изменения в выдаче as is. Для меня Google (и Яндекс) — два монополиста, устанавливающие свои правила, которым в любом случае приходится следовать. Автор статьи Питер Дж. Майерс, как и многие западные специалисты, воспринимает Google как партнера, предоставляющего трафик в обмен на данные для индекса. Но опять же, поисковая выдача — это бесплатный (условно) способ получить пользователя, и даже при драконовских условиях вебмастер должен быть не в себе, чтобы отказаться от подобного источника трафика. И я не вижу какой-либо мало-мальски достойной альтернативы Google на данный момент.
А что думаете вы?

 Теги:
Теги:
