Сканирование изображения и обнаружение в нем объектов — задача № 1 в обработке картинок и компьютерном зрении. Поиск по запросу «автоматическое распознавание изображений» на Google Академии выдаст множество статей со сложными уравнениями и алгоритмами от начала 90-х и до наших дней. Это говорит о том, что указанная проблема занимает ученых с самого появления веб-поиска, но она пока не решена.
Основатель cognitiveSEO Рэзван Гаврилас считает, что в ближайшем будущем Google изменит алгоритмы ранжирования изображений, что повлияет на поиск и фактически на поисковую оптимизацию во всем мире. Эту тему Рэзван развивает в данной статье.
Почему умение распознавать объекты в изображениях важно для мирового digital-сообщества?
По мнению эксперта, обнаружение объектов на картинках станет неким дополнительным фактором ранжирования. К примеру, изображение синей собаки будет неразрывно связано с ключевым словом «синяя собака», а не «рыжая собака».
Для SEO это имеет два важных последствия:
- количество нерелевантных результатов при поиске по определенному ключевому слову будет меньше (в зависимости от того, что находится на изображении),
- распознавание объектов в картинке поможет связать контент страницы с этим изображением. Если на странице много фотографий синих собак и других вещей, связанных с собаками, то рейтинг этой страницы, как посвященной собакам, будет выше.
Ещё один вопрос — станет ли распознавание образов началом «новой эры» для манипуляций с объектами на картинках, как новой теневой техники SEO? Нет, потому что алгоритмы поисковых систем в наши дни легко обнаружат такой вид спама.
Google, искусственный интеллект и распознавание изображений
В 2010 году Стэндфордским университетом был впервые проведен конкурс ILSVRC (ImageNet large-scale visual recognition challenge), в рамках которого программисты демонстрируют возможности разрабатываемых ими систем распознавания объектов на изображении.
ILSVRC включает три основных этапа:
- классификация,
- классификация с локализацией,
- обнаружения.
В первом случае оценивается возможность алгоритма создавать правильные «подписи» к изображению (маркировка), локализация предполагает выделение основных объектов на изображении, похожим образом формулируется и задача обнаружения, но тут действуют более строгие критерии оценки.
В случае с обнаружением алгоритм распознавания должен описать сложное изображение с множеством объектов, определяя их местонахождение и точно идентифицируя каждый из них. Это значит, что если на картинке кто-то едет на мопеде, то программное обеспечение должно суметь не просто различить несколько отдельных объектов (например, мопед, человека и шлем), но и правильно расположить их в пространстве и верно классифицировать. Как мы видим на изображении ниже, отдельные предметы были определены и классифицированы верно.
Любая поисковая система с наличием подобной возможности затруднит, чьи-либо попытки выдать фотографии людей на мопедах за фото водителей Porsche посредством манипуляций с метаданными. Алгоритм, способный распознавать объекты, довольно продвинутый и сможет разобрать любое, в том числе и самое сложное изображение.
В 2014 году конкурс ILSVRC выиграла команда GoogLeNet. Название образовано из слов Google и LeNet — одна из реализаций свёрточной нейронной сети. Подобная сеть может быстро обучаться, а также выдавать результаты даже при наличии небольшого объёма памяти за счёт более чем десятикратного сокращения числа параметров, по сравнению с большинством других моделей компьютерного зрения.
В планах Google — создать открытое программное обеспечение, на основе которого будет разработана технология распознавания изображений. Предполагается, что разработки исследовательской команды GoogLeNet будут внедрены в некоторые визуальные сервисы Google, в частности поиск по изображениям и YouTube, а также в Self-Driving Car — систему автоматического управления транспортным средством.
Отметим, что на ILSVRC 2014 предложено множество идей для распознавания объектов, причем они более «продвинутые», чем 2 года назад. В 2014 году число распознанных изображений составило 457 000, тогда как в 2013 году 395 000. В нынешнем году собрали более 60 000 новых изображений, которые были распределены по 200 категориям объектов.
На ILSVRC 2014 была отмечена нейронная сеть DistBelief (с 11-ю уровнями нейронов), которая может идентифицировать объекты независимо от их размера и расположения на картинке. Сеть DistBelief способна к обучению. Именно её Google использует для выявления семантического смысла понятий.
Как действительно происходит распознавание изображений?
В чем принцип работы вышеупомянутой инфраструктуры DistBelief? Она позволяет обучать нейронные сети в распределенной манере, и основана на принципах Хебба и масштабной инвариантности.
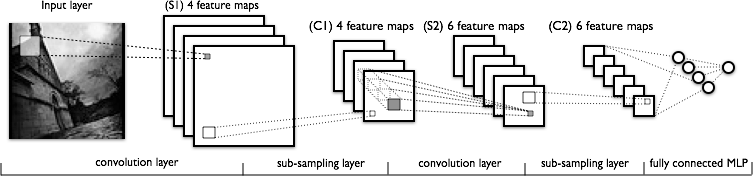
Под термином «нейронные сети» подразумеваются искусственные нейронные сети (ИНС), являющиеся вычислительными моделями, основанными на принципах обучения и распознавания образов. Пример работы алгоритма обнаружения объекта приведен ниже:
Команда GoogLeNet использует определенный тип ИНС — сверточную нейронную сеть, принцип работы которой заключается в том, что отдельные нейроны реагируют на разные (но перекрывающиеся) области в поле зрения. Эти области можно сопоставить воедино, чтобы получить более сложный образ. По словам Рэзвана Гавриласа, это напоминает работу со слоями в редакторе изображений.
Одним из плюсов сверточной нейронной сети является хорошая поддержка перевода — любого типа движения объекта из одного пространства в другое. Инфраструктура DistBelief умеет выделять объект независимо от того, где он находится на картинке.
{kind=link}
Ещё одна полезная возможность инфраструктуры — масштабная инвариантность, согласно которой, свойства объектов не меняются, если масштабы длины умножаются на общий множитель. Это означает, что инфраструктура DistBelief должна четко распознавать изображение, к примеру, «апельсина», независимо от того, большой ли он (на обоях для рабочего стола) или крошечный (на иконке). В обоих случаях объект оранжевый и классифицируется как «апельсин».
Необходимо сказать и о принципе Хебба, согласно которому происходит обучение искусственных нейронных сетей. В книге «Организация поведения: нейропсихологическая теория» постулат Хебба звучит следующим образом: «Если аксон клетки А находится достаточно близко, чтобы возбуждать клетку B, и неоднократно или постоянно принимает участие в ее возбуждении, то наблюдается некоторый процесс роста или метаболических изменений в одной или обеих клетках, ведущий к увеличению эффективности А, как одной из клеток, возбуждающих В».
Рэзван Гаврилас немного упрощает цитату: «Клетки, которые возбуждаются вместе, связываются вместе». В случае с ИНС «клетки» стоит заменить на «нейроны». Выстраивая дальнейшую аналогию, можно сказать, что программное обеспечение будет в состоянии обучать себя, чтобы постоянно совершенствоваться.
{kind=link}
Google рекрутирует специалистов в области искусственного интеллекта и распознавания изображений
Собственную технологию распознавания образов Google создает на основе сторонних разработок, например, для этого была приобретена компания-стартап DNNresearch, занимающаяся исследованиями в области распознавания объектов и голоса. DNNresearch представляет собой стартап, на момент поглощения в его штате числились три человека, автоматически ставшие сотрудниками Google. Им выделен грант на поддержку работы в области нейронных сетей. Новые технологии Google может применить для улучшения качества поиска по картинкам.
Согласно стратегии компании Google, многие решения с открытым исходным кодом остаются доступны для других компаний. Это делается для развития рынка. Как считает Рэзван, зачем душить конкурентов, когда вы можете позволить себе купить его спустя некоторое время?
Ещё одно интересное приобретение Google — компания DeepMind, в которую инвестировано 400 миллионов долларов. Это и многие другие приобретения направлены в первую очередь на то, чтобы привлечь в Google квалифицированных специалистов, а не какие-то готовые решения. Подобные шаги по покупке компаний — свидетельство гонки Google, Facebook и других интернет-компаний за «мозгами» для дальнейших разработок в области искусственного интеллекта.
Google+ уже использует обнаружение объектов в картинках. На очереди Google Поиск?
На самом деле, алгоритм обнаружения изображений на основе нейронной сети уже больше года работает в Google+. Часть кода программного обеспечения представленного на ILSVRC, использовалась для улучшения алгоритмов Google+, а именно — для поиска конкретных типов фотографий.
Технология распознавания изображений от Google имеет следующие особенности:
- Алгоритм Google учитывает соответствие объектов на веб-изображениях (крупный план, искусственное освещение, детализация) с объектами на естественных фотографиях (средний план, естественный свет с тенями, разная степень детализации). Другими словами — цветок должен оставаться цветком даже на изображениях с другим разрешением или условий освещения.
- Некоторые специфические визуальные классы выведены за рамки общих единиц. Например, в большом списке из наименований цветов, которые различает алгоритм, отмечены некоторые отдельные растения, например, гибискус или георгин.
- Алгоритму распознавания изображений Google также удалось научиться работать с абстрактными категориями объектов, выделяя то или иное количество картинок, которые могли бы быть отнесены к категориям «танец», «еда», «поцелуи». Это занимает куда больше времени, чем простое выявление соотношений «апельсин — апельсин».
Классы с разным значением также обрабатываются хорошо. Пример — «автомобиль». Это точно снимок автомобиля, если на нём мы видим весь автомобиль? Считается ли изображение салона машины фотографией автомобиля или уже чем-то другим? На оба вопроса мы бы ответили утвердительно, также поступает и алгоритм распознавания Google.
Нельзя не отметить, что система распознавания изображений пока ещё недоработана. Однако даже в «сыром» виде алгоритм Google на голову выше всех предыдущих разработок в сфере компьютерного зрения.
Технология распознавания изображений — часть Графа знаний Google?
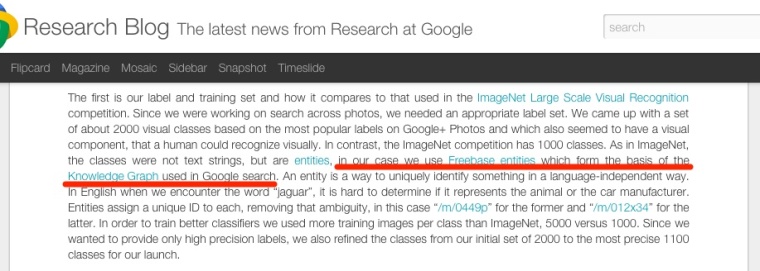
Новый алгоритм Google — часть «машинного обучения», которое отчасти реализовано в Графе знаний. В нем находятся entities — объекты, предназначенные для замещения символов, которые не могут встречаться в «чистом» виде в HTML-тексте, например, символа «
Каждый объекты и каждый класс объектов получают уникальный код, благодаря чему животное «ягуар» никогда не перепутается с одноименной маркой автомобиля. На основе этих кодов алгоритм распознавания может пользоваться базой знаний. Фактически Google создает «умный поиск», который понимает и переводит ваши слова и изображения в реальные символьные объекты.
{kind=link}
Как технология обнаружения объекта в изображениях может повлиять на SEO?
Возможность распознавания изображений может быть полезна везде, где требуется узнать, что находится на картинке.
С точки зрения обычного SEO умение распознавать изображения является огромным шагом вперед. Это способствует повышению качества контента, так как обмануть поисковик с помощью неверной маркировки фотографий или их огромного количества становится почти невозможно.
Хороший визуальный контент (то есть высокое качество изображения, четко видимые объекты, актуальность фото), вероятно, будет играть важную роль во всем, что касается визуального поиска.
Если вы хотите, чтобы ваш рисунок был первым среди изображений по запросам «Yellow Dog», то оптимизацию придется начать с указания типа вашего снимка и перечисления содержащихся в нем объектов.
Заключение
Способность человека распознавать множество объектов и распределять их по категориям является одной из самых удивительных возможностей зрительного восприятия, компьютерных аналогов которой пока не придумано. Однако Google уже делает шаги вперед, например, ему уже принадлежит патент на автоматическое масштабное видеораспознавание объектов с 2012 года.
Итак, по мнению Рэзвана Гавриласа, органические результаты поиска Google в ближайшем времени подвергнутся изменению. Поисковик перейдет «от строк к вещам», фактически интегрировав в поисковый ландшафт свой Граф знаний. Изменятся и алгоритмы поиска, которые, вероятно, будут связаны с фактическими объектами в содержании и определении того, как эти объекты будут связаны друг с другом.