
Мы постоянно имеем дело с информацией — запросы, показы, клики и т.д. и т.п. Многие оптимизаторы заимствуют метрики и не вникают в суть данных. Этот подход, безусловно, прост и быстр. Но при этом малоэффективен, поскольку пользоваться минимальным набором традиционных метрик — значит лишить себя кучи полезных выводов.
По сути, аналитика сводится к сбору и анализу данных. Здорово, если масштаб компании позволяет собирать данные решениями своей команды разработчиков. Если нет — вам наверняка будут интересны простые и доступные инструменты. Опишем некоторые из них:
— фантастически удобный плагин к FireFox для извлечения структурированных данных из веб-контента. Плагин умеет извлекать данные самостоятельно, либо по предопределенному шаблону. Можно использовать регулярные выражения и листать страницы. Например, вот результат парсинга страницы выдачи Яндекса по запросу «продвижение сайтов» с извлечением переколдовок:
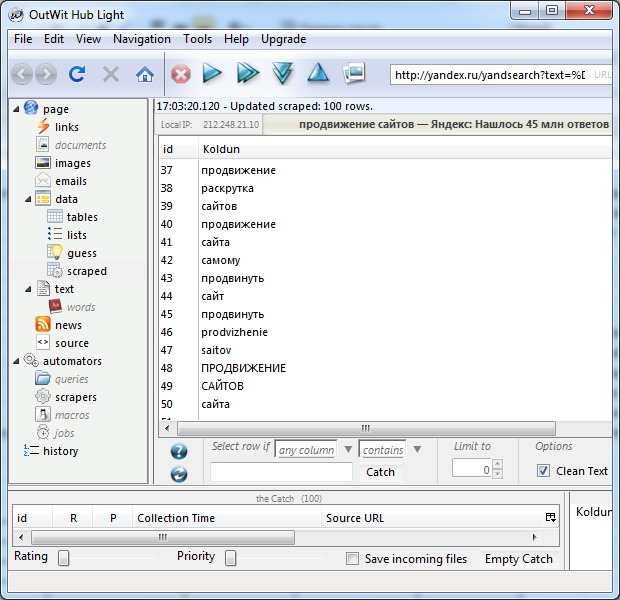
Версия Outwit Pro позволяет создавать процессы и макросы и, однозначно, стоит 30 долларов, что за нее просят. Но и бесплатная Light-версия весьма полезна.
предоставляет много возможностей для повышения эффективности поискового продвижения. Самые очевидные применения:
- Оценка стоимости конверсии в срезах по запросам и по источникам трафика позволяет сосредоточить усилия на действительно полезных запросах, отбросив конкурентные, но малоэффективные (достаточно штатных возможностей Google Analytics).
- Выгрузка ключевых слов, по которым были зафиксированы переходы из органического поиска с дальнейшей проверкой частотностей этих запросов и текущих позиций сайта. Этот способ позволяет быстро выявить наилучшие точки приложения усилий оптимизатора. Для массовой обработки ключевых слов «на коленке» удобен .
При выгрузке ключевых слов из Google Analytics максимальный объем csv-файла ограничен 500-ми запросами. Сократить рутину можно, как минимум, двумя способами:
- Если при построении нужного отчета в Google Analytics добавить к url параметр &limit=50000, выгрузка по ссылке «csv» магическим образом будет расширена до 50000 запросов.
- У Google Analytics есть API, которое можно использовать для получения данных. Вот .
— любопытный инструмент для небольших задач автоматизации сбора и обработки данных. Например, мы хотим отслеживать посты на Searchengines.ru, созданные авторитетными SEO-специалистами. В Yahoo Pipes это делается запросто, берем RSS-фид и фильтруем его по полю «автор» (item.dc:creator):
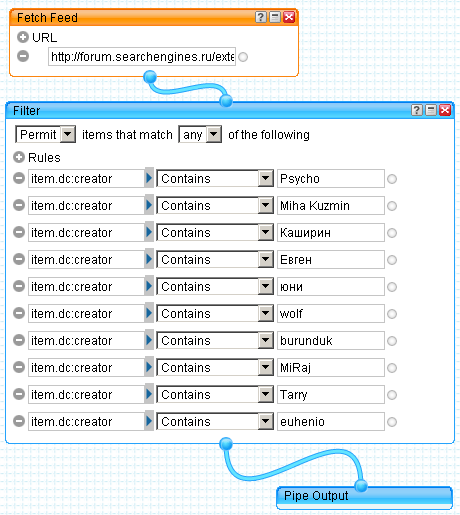
Результат доступен в виде RSS-фида или уведомлений . Просто и удобно. .
Скажу несколько слов о регулярных выражениях. Для SEOшников, не имеющих опыта веб-разработки или программирования это может быть серьезным «белым пятном». Суть регулярных выражений — в компактной и чрезвычайно мощной процедуре поиска (и замены) в текстах. Существует несколько реализаций, но общие идеи неизменны. Многие продвинутые текстовые редакторы (например, , ) позволяют использовать регулярные выражения и это, поистине, бесценно.
Разумеется, собранные данные нужно хранить в легкодоступной для обработки форме. Если данных немного — Excel в помощь. Стандартные фильтры и сортировки, плюс функции «счетесли», «суммесли», «впр» и использование табличных формул (формул массива, Ctrl-Shift-Enter) закроют основные потребности в выборке данных. Для больших объемов данных стоит использовать базы данных (MySQL, PostgreSQL и т.д.). SQL несложен и эффективен.

 Теги:
Теги:






