
 Ни для кого из вас не секрет, что для продвижения сайтов нужны ссылки и желательно много и бесплатно. Где же их взять? Существует сайты, которые получают контент благодаря пользователям. Например, каталоги сайтов, статей и компаний. Базой называется собрание адресов таких сайтов.
Ни для кого из вас не секрет, что для продвижения сайтов нужны ссылки и желательно много и бесплатно. Где же их взять? Существует сайты, которые получают контент благодаря пользователям. Например, каталоги сайтов, статей и компаний. Базой называется собрание адресов таких сайтов.
Вне зависимости от того, какую базу вы собираете, можно найти сайты по соответствующим запросам в поисковых системах. Этот процесс называется парсингом выдачи. Обычно парсится Google и на это есть три причины:
1. Хорошее качество поиска
2. Высокая скорость ответа
3. Наличие оператора inurl:
Этот оператор имеет следующий вид inurl:«содержание url искомых страниц ». С помощью этого оператора можно искать конкретные движки сайтов. В Яндексе нет аналогов этому оператору.
Например, чтобы найти большую часть каталогов нужно в поисковой строке Google ввести запрос: или .
Правда, с использованием этого оператора нужно знать несколько моментов. Первое - для Google большинство спецсимволов - то же самое, что и пробел. Это плохо потому, что некоторые движки будут парситься с огромным количеством мусора. Например, в выдаче по запросу inurl:«xxx/yyy» можно встретить как страницы, содержащие «xxx?yyy», так и страницы, содержащие «xxx.yyy».
Второе - для многих запросов поисковик при использовании этого оператора показывает не всю выдачу как раз для того, чтобы ограничить дорвейщиков.
Иногда я запрос с оператором inurl заменяю запросом в виде -intext:"XXX" -intitle:"XXX" "XXX". Другими словами, мы говорим Google искать XXX, но не в тексте и не в заголовке, а кроме этого есть только URL. Правда, такая замена не равнозначна: если искомый XXX есть в заголовке или в тексте и одновременно в URL, то такая страница показана не будет.
При парсинге есть обычно две задачи:
1. Напарсить как можно больше URL.
2. Захватив при этом как можно меньше мусора - страниц, которые нам не нужны.
Для решения первой задачи используется следующим метод. Например, по запросу «XXX» выдается только 1000 сайтов, а в Интернете их, скажем, полмиллиона. Чтобы увеличить выдачу, добавим в к основному запросу(ам) «бесполезные» уточнения:
«XXX» фирма
«XXX» компания
«XXX» найти
«XXX» сайт
«XXX» страница
«XXX» главная
В качестве уточнения берем общеупотребительные слова, которые могут встретиться на любом сайте. Хотя более полезно сайты разделять на непересекающиеся категории: только английский, только русский, только украинский. Либо добавлять поиск по зоне домена inurl:«.com», inurl:«.net»… Возьмем, например, запрос «каталог». Страниц в интернете с таким словом 209 000 000, но нам выдается не больше 1000. Используя шесть запросов
1. Каталог inurl:«.com»
2. Каталог inurl:«.net»
3. Каталог inurl:«.biz»
4. Каталог inurl:«.ru»
5. Каталог inurl:«.info»
6. Каталог inurl:«.org»
Мы получим не 1000, а 6000 каталогов. Применив находчивость, можно получить несколько десятков тысяч URL. Но большинство будет мусором.
Порой проблемы с мусором весьма существенные, потому приходится перед парсингом качество выдачи по каждому запросу проверять вручную, чтобы автомат не захватил много ненужных сайтов, а вы потом не мучились, проверяя их. Помогает нахождение «полезных» уточнений.
Например, при запросе можно наблюдать много мусора, этому нужно добавить уточнение . Можно пойти дальше и отфильтровать «серые» каталоги
Вручную собирать результаты парсинга долго, скучно и непродуктивно. Поэтому существуют соответствующие программы - парсеры, которые запоминают выдачу по запросам и сохраняют их. Большинство парсеров, либо платные сами по себе, либо входят в комплект других платных приложений.
Использование бесплатного десктопного парсера
Программа не требует установки и поэтому пользоваться ей можно сразу после закачки.Работает программа только с Google и обладает спартанским интерфейсом, но, как говорится, «дареному коню в зубы не смотрят».
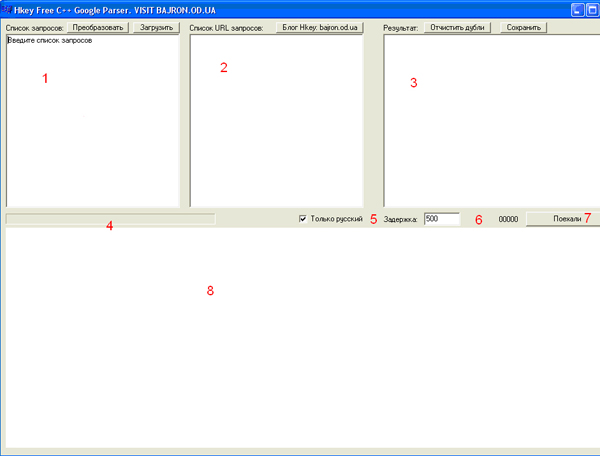
1. Поле ввода запросов. Сюда нужно ввести список запросов к Google, например, inurl:«xxx» (обратите внимание на то, что оператор и запрос пишутся без пробела).
2. Поле ввода-вывода URL запросов к Google. В этом поле будет появляться, какие URL Google парсятся при выполнении запросов. При желании можно самому сюда ввести список urls Google, которые нужно отпарсить. К примеру: «http://www.google.com.ua/search?hl=ru&q=XXX&btnG=%D0%9F%D0%BE%D0%B8%D1%81%D0%BA+%D0%B2+Google&meta=»
3. Поле вывода результа – URL сайтов, которые нашлись.
4. Процент выполненения задачи
5. Фильтр на парсинг только русскоязычных сайтов
6. Задержка в тысячных долях секунды. От 0 до 60 000. Задержка нужна, чтобы гугл не понял, что его парсит программа и не заблокировал вам доступ к ресурсам.
7. Кнопка «Поехали» запускает парсинг.
8. Показывает страницу, которая парситься в данный момент. Пользы особой нет, скорее для развлечения.
Дополнительно над полем ввода запросов (1) есть кнопка «преобразовать», которая преобразует запросы inurl:«XXX» в -intext:"XXX" -intitle:"XXX" "XXX"
Как пользоваться программой? Ввести в левое поле ввода(1) список запросов, подождать и копировать из правого поля ввода(3) результат. Потом отчистить дубли доменов, например, с помощью http://bajron.od.ua/?p=67. Реузльтаты хранятся в формате списка URL найденных сайтов.
Программа избавляет от большей части рутинной работы и парсит намного быстрее человека.

 Теги:
Теги:





