1. Введение в проблему
В настоящее время все острее и острее встает проблема дублирования информации в интернете. Чаще всего такое дублирование совершается умышленно, с нарушением авторских прав. Злоумышленники используют авторский контент для наполнения собственных сайтов, чтобы извлекать для себя выгоду.
Такое дублирование информации ухудшает выдачу поисковых систем, вследствие чего последние активно борются с этим явлением. Действительно, если пользователь получает по запросу 10 одинаковых документов («одинаковость» определяется пользователем по сниппетам), это вряд ли добавляет популярности поисковику. Несколько лет назад такая ситуация наблюдалась в Рамблере, вследствие чего поисковик растерял часть своего рейтинга. Однако сейчас Rambler отфильтровывает и скрывает дубликаты.
Также нужно отметить, что дублирование контента засоряет индекс поисковика, ему становится труднее выдавать быстрые ответы пользователю. При этом все документы нужно регулярно индексировать, а появление новых документов с неоригинальным контентом явно вредит скорости индексации.
2. Теория по определению «нечетких дубликатов»
a. Что такое «нечеткий дубль»
Для начала нужно определиться с терминологией. Единого мнения по этому поводу в seo еще нет, и поэтому данная терминология отталкивается просто от здравого смысла.
Дубль (дубликат) web-документа – точная копия web-документа. «Нечеткий дубликат» web-документа – web-документ, частично измененный в содержательной части и/или в части форматирования (использование других тегов html для оформления страницы).
Мы будем трактовать «дубликат web-документа» только с точки зрения поисковой системы, а не пользователя. Поэтому мы не будем рассматривать такое явление как «копирайтинг», т.е. переписывание текста специально для поисковых систем с использованием других слов, но с сохранением общего смысла. Такой текст для поисковика будет всегда оригинальным, т.к. смысл текста компьютеры пока различать не могут.
Существует несколько основных методов определения дубликатов.
b. Метод «описательных слов»
Данный метод работает по следующему принципу.
Сначала формируется небольшая (ок. 2000-3000 слов) выборка. Выборка должна удовлетворять следующим условиям:
- с ее помощью можно достаточно полно описать практически любой документ в сети
- описание документа не должно быть при этом избыточным
Таким образом, для формирования выборки нужно отбросить слова, которые наиболее и наименее употребительны, т.е. не учитывать стоп-слова и различные узко тематические термины. Также в выборку не попадают прилагательные, так как они не несут в русском языке смысловой нагрузки.
Далее каждый документ сопоставляется с выборкой и рассчитывается вектор, размерность которого равна количеству слов в выборке. Компоненты вектора могут принимать два значения – 0 или 1. 0 – если слова из выборки нет в документе, 1 – если слово встречается в документе. Далее документы проверяются на дублирование путем сопоставления их векторов.
По такому алгоритму Яндекс определяет нечеткие дубликаты.
c. Метод шинглов
Метод шинглов заключается в следующем. Для всех подцепочек анализируемого текста рассчитывается «контрольная сумма». Контрольная сумма (или "сигнатура") - это уникальное число, поставленное в соответствие некоторому тексту и/или функция его вычисления. Функция вычисления контрольных сумм может преследовать несколько целей: например "невзламываемость" (минимизируется вероятность того, что по значению контрольной суммы можно подобрать исходный текст) или "неповторяемость" (минимизируется вероятность того, что два разных текста могут иметь одну контрольную сумму) - Электронный журнал "Спамтест" No. 27.
Обычно используются следующие алгоритмы вычисления контрольных сумм: fnv, md5, crc. После вычисления контрольных сумм строится случайная выборка из полученного набора. По этой выборке документ можно сличать с другими документами, для которых также предварительно рассчитана выборка.
Данный метод расчета является достаточно ресурсоемким и его можно обойти, незначительно изменив текст, так как, прежде всего, шинглы зависят от расстояния между словами.
Сейчас метод шинглов эволюционировал до алгоритма «супершинглов», при котором стоится ограниченный набор контрольных сумм. Эксперименты на РОМИП привели к следующим результатам – 84 шингла, 6 супершинглов над 14 шинглами каждый. Тексты считаются совпавшими при совпадении хотя бы двух супершинглов из 6.
3. Яндекс и дублирование контента
Официальными лицами неоднократно заявлялось, что Яндекс не рецензент и не будет бороться с проблемой воровства контента в сети.
Вот официальный ответ А. Садовского:
... поиск Яндекса при обнаружении дубликатов пытается определить оригинал документа. Существующие алгоритмы, конечно, несовершенны и мы работаем над их улучшением. Что касается юридического регулирования, поисковые системы пока не могут идентифицировать авторство текста. В случае удаления из сети «тыренного» контента (например, в результате действий правообладателя), Яндекс также удалит его из базы по мере обхода роботом. Этот процесс можно ускорить, воспользовавшись формой
Теперь рассмотрим, а что есть для Яндекса «дубликат документа»? Автор предлагает следующую трактовку. (Если ниже приведенный текст показался вам знакомым, то не думайте плохого, автор не так давно пытался активно обсуждать данную проблему на форумах )))
Существует два вида дубликатов: «нечеткие дубликаты» и «полные дубликаты».
«Нечеткие дубликаты» зависят от сниппета, т.е. определяются фактически запросом пользователя. Происходит это следующим образом.
1. Пользователь задает запрос.
2. Яндекс вычисляет релевантность сайтов запросу и ранжирует сайты, но пока еще не показывает пользователю.
3. Далее Яндекс сравнивает сниппеты отобранных документов на предмет определения дубликатов (возможно, сниппеты сравниваются методом шинглов).
4. И наконец, выдает отфильтрованную выдачу, удаляя некоторые дубликаты (по какому принципу оставляются те или иные документы – неясно; возможно, выбирается самый релевантный документ, и вместе с ним в выдачу попадают наименее похожие на него документы; возможно, играет роль только ссылочное окружение сайтов).
Существование фильтр такого типа косвенно доказывают слова Садовского () и то, что выдача с различными настройками поиска (конкретно, количество отображаемых фрагментов со словами запроса) различная.
При настройках «отображать не более 5 фрагментов» в выдаче больше сайтов, чем при настройках «отображать не более 1 фрагмента». Попробуем запрос «Во & второй & главе & реферата & посвящена & практике & маркетинговой & деятельность & организации & на & примере & сервер & дукса» (запрос задается без кавычек!) - в первом случае (отображать 1 фрагмент в сниппете) в выдаче 21 сайт, во втором (5 фрагментов) – 27 сайтов.
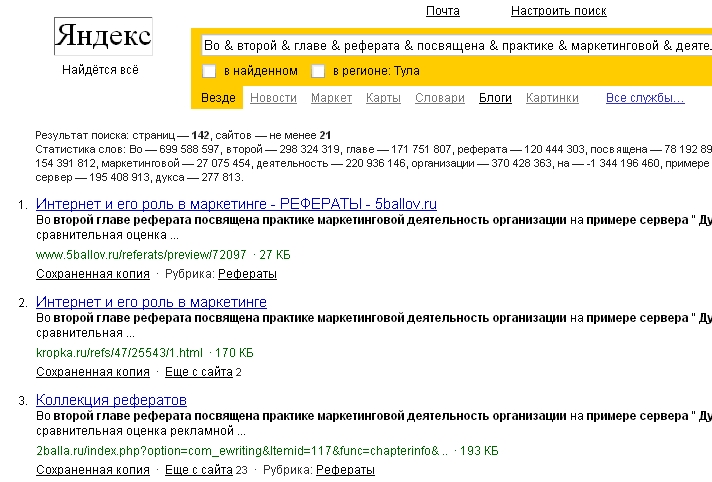
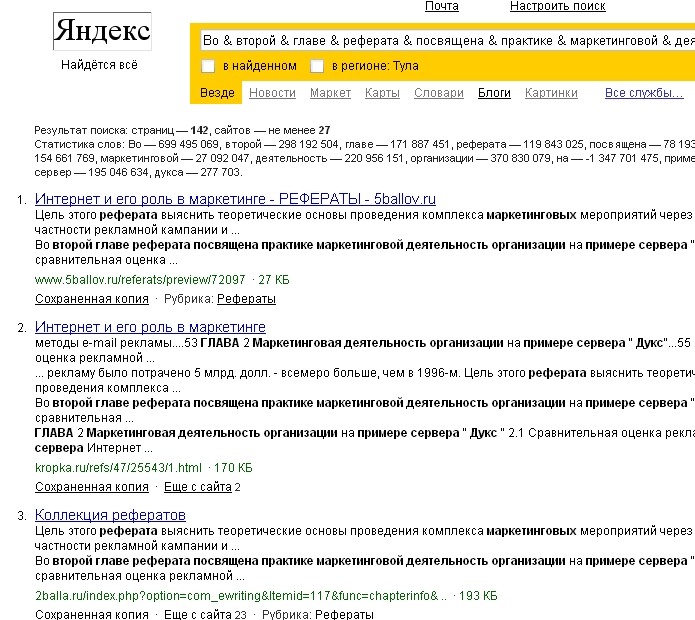
| 1 | http://zoom.cnews.ru/ru/publication/index.php?art_id80=1523 | Оригинал, первая часть статьи |
| 2 | http://www.neograd.ru/firsttimers/howtofind_1/panasonic/test_panasonic_fz50 | полное соответствие |
| 3 | http://www.apitcomp.ru/analytic/genre3/page637 | вся статья |
| 4 | http://www.toplist.ru/card/35859 | вся статья + еще доп. информация |
| 5 | http://foto-focus.ru/forum/showthread.php?mode=hybrid&t=316 | Форум. Статья целиком |
| 6 | http://nmp4.ru/index.php?act=Print&client=printer&f=223&t=3323 | форум + много другой информации |
| 7 | http://www.media.nrd.ru/index.php?showtopic=3323&st=100 | форум + много другой информации |
| 8 | http://www.ledshop.ru/cgi-bin/nph-proxy.cgi/010110A/http/zoom.cnews.ru/ru/publication/index.php=3fart_id80=3d1523 | полная копия |
| Станица | тИЦ | Рубрика каталога | PR | PR стр-цы |
| zoom.cnews.ru/ru/publication/index.php?art_id80=1523 | 3800 | Да | 6 | 4 |
| www.neograd.ru/firsttimers/howtofind_1/panasonic/test_panasonic_fz50 | 170 | Да | 5 | 0 |
| www.apitcomp.ru/analytic/genre3/page637 | 700 | Да | 4 | 0 |
| www.toplist.ru/card/35859 | 110 | Нет | 3 | 0 |
| foto-focus.ru/forum/showthread.php?mode=hybrid&t=316 | 0 | Нет | 1 | 0 |
| nmp4.ru/index.php?act=Print&client=printer&f=223&t=3323 | 0 | Нет | 0 | 0 |
| www.media.nrd.ru/index.php?showtopic=3323&st=100 | 40 | Нет | 0 | 0 |
| www.ledshop.ru/cgi-bin/nph-proxy.cgi/010110A/http/zoom.cnews.ru/ru/publication/index.php=3fart_id80=3d1523 | 0 | Нет | 0 | 0 |
| Страница | тИЦ | YACA | LS | LP | PR | Page PR |
| saturn-plus.ru/ | 70 | Да | 54 | 20349 | 3 | 3 |
| saturn.24online.ru/ | 0 | Нет | 1 | 1 | 0 | 0 |
| www.3dnews.ru/digital/lumix_fz50/print | 11000 | Да | 0 | 0 | 6 | 2 |
| fotomag.com.ua/handbook14.html | 400 | Да | 0 | 0 | 4 | 0 |
| Deshevshe.net.ua/ua/review-73/4.html | 80 | Нет | 0 | 0 | 4 | 0 |
| Ephotolink.ru/?mod=articles&act=show&sort=date&page=9 | 1400 | Да | 0 | 0 | 4 | 1 |
| mobil-up.com/tsifra/foto/novoe_pokolenie_ultrazumov_ot_panasonic.html | 0 | Нет | 0 | 0 | 0 | 0 |
| uaport.net/UAit/?CGIQUERY=0&lang=RUS&cli=1&dtb=146&… | 4300 | Да | 0 | 0 | 6 | 0 |
| www.velc.ru/podderjka/stati/lumix_fz50/ | 120 | Да | 0 | 0 | 3 | 0 |
| Ephotolink.tkat.ru/?mod=articles&id_article=21007 | 10 | Нет | 0 | 0 | 3 | 0 |
| www.ru-coding.com/rss.php?p=501 | 130 | Да | 0 | 0 | 3 | 0 |
| www.toprunet.com/article.php?id=6388 | 200 | Нет | 0 | 0 | 3 | 0 |
| www.dphotographer.com.ua/camera/from/2/ | 90 | Нет | 0 | 0 | 4 | 0 |
| www.asmedia.ru/news/id8242.html | 400 | Нет | 0 | 0 | 3 | 0 |
| www.mega-bit.ru/obzor/read/?id=70 | 40 | Нет | 0 | 0 | 3 | 0 |
| www.audiovideophoto.ru/panasonic1.html | 0 | Нет | 0 | 0 | 0 | 0 |
| www.foto-piter.ru/news/2006/12/01/127/ | 10 | Нет | 0 | 0 | 2 | 0 |
| www.megastoke.ru/item951928/panasonic-lumix-dmc-fz50.html | 20 | Нет | 0 | 0 | 1 | 0 |
| www.novoe.nnov.ru/articles/?parent_id=33 | 0 | Нет | 0 | 0 | 0 | 0 |
| iwy.com.ua/top.php?p=326 | 0 | Нет | 0 | 0 | 0 | 0 |
| www.5-uglov.ru/articles_view.php?id_news=1222 | 90 | Да | 0 | 0 | 3 | 0 |
| www.techhome.ru/catalog/photo/article_17112.html | 950 | Да | 0 | 0 | 5 | 3 |
| www.panasonic-spb.ru/articles_view.php?id_news=1222 | 0 | Нет | 0 | 0 | 1 | 0 |
| new-articles.ru/page_215.html | 40 | Нет | 0 | 0 | 3 | 0 |
| www.ekvator-hifi.ru/articles_view.php?id_news=1222 | 10 | Нет | 0 | 0 | 1 | 0 |
| shop.key.ru/shop/goods/36608/ | 230 | Нет | 3 | 18 | 4 | 0 |
| www.pc-shop.kz/index.php?g_id=1711 | Нет | 0 | 0 | 3 | 0 | |
| Portalink.ru/portal/ecamera/infoat_15269.htm | 110 | Нет | 0 | 0 | 3 | 3 |
| www.rusdoc.ru/articles/13085/ | 1100 | Да | 3 | 13 | 5 | 1 |
| www.docs.com.ru/articles.php?p=509 | 220 | Нет | 0 | 0 | 4 | 0 |
| e-libed.ru/a31/ | 0 | Нет | 1 | 17 | 0 | 0 |
| dvdlink.ru/portal/Ecamera/infoat_15269.htm | 140 | Нет | 0 | 0 | 3 | 0 |
| www.articlesearch.ru/a3b856d85.html | 0 | Нет | 0 | 0 | 0 | 0 |
| www.bestarticles.ru/a31/ | 0 | Нет | 1 | 5 | 2 | 0 |
| www.temu.ru/a31/ | 0 | Нет | 0 | 0 | 2 | 0 |
LP – ссылающихся страниц, LS – ссылающихся сайтов, Page PR – PR страницы, PR – PR главной страницы сайта.
Аналогичная картина – критерии фильтрации совершено неясны. Однако, если посмотреть на сниппеты, то мы увидим, что у страниц на сайтах uaport.net, , portalink.ru сниппеты несколько отличаются от сниппетов других сайтов и поэтому первый и третий сайт не фильтруется.
Что сказать в итоге? Прежде всего, конечно нужно еще много экспериментировать и анализировать, однако уже видно, что решение о фильтрации «нечетких дубликатов» основывается на анализе многих факторов, главным из которых является оригинальность сниппета.
4. Google и дублирование контента
Google стремится выдавать на запросы пользователя сайты только со свежим и уникальным контентом.
Google считает, что пользователи не хотят видеть дубликаты в результатах поиска, поэтому такие документы скрываются в suggestion results. Если пользователь все же захочет увидеть дубликаты (например, это веб-мастер, который хочет выяснить, кто ворует контент с его сайта), то он должен добавить параметр «&filter=0» в конец URL.
Google считает, что идентификация автора контента поможет улучшить поиск. Однако отмечает, что такие способы определения первоисточника как фиксация даты создания документа или регистрация контента авторами в специальных сервисах не эффективны. Пока Google ориентируется по большей части на авторитетность ресурса и количество входящих ссылок. Поэтому вполне возможна ситуация, когда какой-нибудь известный ресурс позаимствовал статью, например, у специализированного ресурса, далее большинство узнало о статье из известного ресурса и поставило на него ссылки; в итоге Google определит известный сайт как первоисточник…
В случае дублирования контента на одном сайте (например, страница-оригинал и страница для печати) Google предлагает веб-мастерам активно использовать robots.txt. Также предлагается отказаться от использования идентификаторов сессий, так как это тоже может привести к дублированию контента. Т.е. поисковик может проиндексировать одну и ту же страницу, но с разным url, отличающимся значением параметра sessid.
5. Над чем можно поэкспериментировать и как это лучше сделать
Итак, мы выяснили основные моменты по проблеме дублирования контента. Принципы работы фильтра (в частности Яндекса) достаточно просты, однако определить в точности, как учитываются различные факторы достаточно сложно.
Итого, что нужно проверить экспериментальным путем:
- Как дубликаты фильтруются в момент выдачи? По какому принципу?
- Метод «описательных слов» - как формируется выборка слов и как сравниваются вектора?
- По какому принципу выкидываются «полные дубликаты»?
Можно предложить следующий вариант:
- Создаем один сайт с оригинальным контентом. Немного спамим его, чтобы он проиндексировался. Создаем далее некоторое количество клонов (дубликатов). Клоны можно сделать различным образом: перемешать слова первоисточника, сделать рерайтинг, взять отдельные абзацы. Клоны можно разместить как на отдельных сайтах (на нормальных и обычных хостингах) так и на внутренних страницах сайтов. Можно частично проспамить клоны. Потом оцениваем результат умозрительно и делаем выводы.
- Определить принципы, по которым фильтруются «нечеткие дубликаты» можно по методике, описанной выше, т.е. просто путем анализа отфильтрованных сайтов.
6. Дополнительная литература
- (русский вариант ) – «Эффективный способ обнаружения дубликатов web доку-ментов с использованием инвертированного индекса» (Сергей Ильинский, Максим Кузьмин, Александр Мелков, Илья Сегалович)
- – скрипт определения дубликатов методом шинглов.
- - Электронный журнал "Спамтест" No. 27
- - комментарии Сегаловича
-


 Теги:
Теги: