
применительно к результатам работы поисковой системы —
— степень соответствия запроса и найденного, уместность результата.
Это субъективное понятие…
«Википедия»
«Отсортировано по релевантности» – как много в этой фразе… для простого веб-мастера. Релевантность сайта, релевантность выдачи поисковой машины, оценка релевантности, увеличение релевантности – всё суть, чаяния и головная боль любого, кто связан с продвижением сайта в Сети.
«При поиске в Интернет важны две составляющие – полнота (ничего не потеряно) и точность (не найдено ничего лишнего). Обычно это все называют одним словом – релевантность, то есть соответствие ответа вопросу», – говорит нам Яндекс. «Хорошо, и где же критерии?» – спрашиваете вы. Критерии – это камень преткновения между поисковыми системами, пользователями и оптимизаторами.
В чем же, собственно, проблема?
Вокруг релевантности
Стремительное и бесконтрольное разрастание всемирной паутины автоматически отвело поисковым машинам заглавную роль в виртуальном мире. Для любого сайта поисковые машины - это фактически окошки в виртуальный мир, универсальная и наиболее действенная рекламная площадка. Именно поэтому на этой площадке развертываются самые «кровавые» бои оптимизаторов за всемирную известность собственных веб-ресурсов.
Работая над основной своей задачей – точностью поисковой выдачи – поисковые машины были вынуждены разрабатывать и совершенствовать критерии релевантности. Основой стали так называемые «внутренние» критерии – плотность ключевых слов на странице, объем содержания, текст заголовков и многое другое. Однако после того как в интернете появились так называемые дорвей-страницы, создаваемые исключительно с целью всеми правдами и неправдами поднять рейтинг сайта, появилась и насущная потребность в разработке «внешних» критериев релевантности.
Принцип цитируемости
В основу внешних критериев релевантности лег давно известный и широко применимый в мире «принцип цитируемости», который также называют ссылочной цитируемостью или ссылочной популярностью. Данный принцип подразумевает, что релевантность сайта должна определяться его популярностью в виртуальном мире – тем, как и сколько на него ссылаются другие сайты. Вполне разумное решение – чем больше сайтов рекомендуют посетителям зайти на чей-то ресурс, тем более высокую оценку получает он от поисковой машины (когда в тексте ссылки есть искомый термин, конечно). Налицо повышение качества поиска.
Оптимизаторы vs. поисковые машины
Изначально поисковые машины, учитывая популярность ссылок, считали количество ссылающихся сайтов или страниц, выводя самую простую закономерность – чем больше таких страниц существует, тем популярнее и важнее сайт. Однако, по мере того как борьба за первые места в выдаче поисковиков ужесточалась, все более давало себя знать желание раскрутчиков сайтов обмануть поисковую машину. Для начала появилось множество специальных сайтов, так называемых «ферм ссылок», или «FFA (Free for All)», на которых любой веб-мастер мог бесплатно разместить ссылку на свой сайт. Такая методика искусственного повышения популярности ссылок некоторое время вполне работала. Однако очень быстро популярность FFA сыграла с раскручиваемыми сайтами нехорошую шутку: появились автоматические программы, которые одновременно регистрировали ссылку на тысячах «ферм». FFA-сайты, как правило, работали по принципу конвейера – новые ссылки вытесняли старые в низ страницы. Поскольку количество ссылок на странице ограничено, а скорость продвижения по мере автоматизации увеличилась до нескольких сотен ссылок в час, то, собственно, время присутствия вашей ссылки в «нужном месте» сводилось буквально до пары минут. Времени, a priori, недостаточном для индексации ссылки поисковой машиной.
Таким образом порочная система изжила сама себя. Тем не менее проблема осталась. И поисковые сайты были вынуждены обратить внимание не только на количество, но и на качество ссылок.
Google Page Rank…
У истоков нового алгоритма ранжирования первым оказался Google. Он ввел понятие «случайного сёрфера» – то есть абстрактного человека, который бродит по Сети, переходя с ссылки на ссылку и просматривая все новые и новые страницы. Смысл нового алгоритма, получившего название Page Rank, сводился к попытке оценивать каждый документ с учетом его веса в среде всех других проиндексированных документов Сети, ссылающихся на оцениваемый. То есть, по сути, Page Rank – это попытка поисковой машины предсказать и использовать в качестве критерия вероятность того, что случайный пользователь попадет на ту или иную страницу. Несомненно, что данная система оценки релевантности выглядит гораздо более «помехоустойчивой», а значит, максимально полезной для пользователей поисковых машин и минимально пригодной для искусственной накрутки популярности веб-ресурсов.
Как работает данный алгоритм? Для начала ищутся все страницы, в которых есть слова из запроса пользователя поисковой машины. Найденные страницы ранжируются на основе «внутренних» критериев релевантности. Учитывается количество ссылок на сайт. Результаты корректируются с помощью Page Rank каждой страницы. Непосредственная формула для присвоения странице «разряда» (Rank) выглядит следующим образом:
где:
R(A) – Page Rank страницы;
R(Bi) – Page Rank ссылающейся страницы Bi;
Ni – количество ссылок на странице B;
С – коэффициент сглаживания (затухания), используется для страницы или группы страниц.
Препятствует «накрутке» Page Rank. Обычно равен 0,85.
Google ранжирует значение PR от 0 до 10. При этом связь значения PR, которую показывает Google ToolBar (специальный сервис Google, отображающий PR страницы) и абсолютного значения имеет следующий вид:
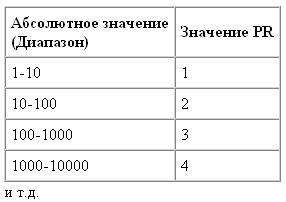
Из этой зависимости очевидно следующее: увеличить значение PR с 1 до 2 будет существенно легче, чем, к примеру, с 6 до 7. Англоязычные сайты средней раскрученности дают PR на уровне 4-5. Если данный критерий выше 6 – ресурс можно считать очень хорошо раскрученным. Более высокое значение PR – задача, решение которой под силу крупным мировым корпорациям. Тот же Google или Microsoft. Одни из самых популярных российских веб-ресурсов, такие как Rambler или Lenta.ru, демонстрируют значение Page Rank, равное 7-8.
Теоретически можно предположить, что создание n-го количества страниц и проставление на них ссылки на одну может обеспечить ей хорошее значение цитируемости. Однако на практике реализация данной идеи требует значительно больше времени, чем увеличение PR с помощью внешних ссылок.
В целом, идея подобного алгоритма оказалась весьма удачной, и со временем ноу-хау Google переняли большинство поисковых систем
…и Яндекс тИЦ
Но, несмотря на свою заслуженную популярность, формула Page Rank никак не учитывала «вес» ссылок, то есть их качественную характеристику. Именно поэтому Яндекс разработал собственный алгоритм учета внешних ссылок.
Тематический индекс цитирования (тИЦ) в поисковой системе Яндекс был создан, чтобы определять релевантность веб-ресурсов в Яндекс.Каталоге, принимая во внимание качество ссылок на них с других сайтов. Качество ссылки или её «вес» рассчитывались по специально разработанному алгоритму, учитывающему, в первую очередь, количество ссылок и тематическую близость ссылающихся на ресурс сайтов. При этом, однако, ссылки с иностранных ресурсов Яндексом были полностью проигнорированы. С учетом того, что сайтов не .ru и не .su в мире более, чем достаточно, погрешность окончательных расчетов может быть весьма значима для пользователя. С другой стороны, наличие сайта в западных каталогах, даже очень популярных, никак не поможет увеличить тИЦ.
Что касается оценки тематической близости ссылающихся сайтов, то Яндекс определяет схожесть тематики по расположению ресурсов в собственном каталоге. Для сайтов, не входящих в каталог, применяются другие технологии.
тИЦ можно посмотреть с помощью различных сервисов. Однако тИЦ не является критерием релевантности поисковой выдачи Яндекса. Только для сортировки собственного каталога! Для поисковой системы высчитывается уже другой индекс – так называемый вИЦ (взвешенный индекс цитирования). Который, увы, обычным пользователям недоступен. Поэтому всем заинтересованным степень «раскрученности» сайта приходится приблизительно оценивать по тИЦ.
Закрытый алгоритм
Итак. Заявленные формулы успеха (релевантности), находящиеся в открытом доступе для оптимизаторов веб-ресурсов, на самом деле недостаточно полны, чтобы уповать на них в реальной «борьбе» за популярность своего сайта. В то же время, как мы уже говорили, усложнение исходных алгоритмов поисковых машин отчасти провоцируют сами оптимизаторы. Разработчики поисковых машин вынуждены балансировать между попыткой найти факторы, которые трудно «накрутить», но при этом достаточные и оптимальные, чтобы справляться с основной задачей – адекватно оценивать релевантность сайтов.
Ссылочное ранжирование в этом смысле весьма перспективно. Но несомненно и то, что поисковые машины будут усложнять алгоритмы поиска и анализа ссылок (а также вводить в обиход и новые критерии, например, TrustRank). Более того, все нюансы алгоритмов будут продолжать держать в тайне от общественности, дабы избежать «злоупотреблений» со стороны оптимизаторов.
Подтверждением этому служит уже упомянутый взвешенный индекс цитирования Яндекса. Полностью параметры, которые учитывает Яндекс при расчете вИЦ, неизвестны. Однако эксперименты показывают, что, кроме количества ссылок и тематической близости сайтов, на результат поиска также влияют и расположение ссылки (главная страница или подраздел) и якорный текст. Кроме того, Яндекс из расчета индекса исключает ссылки, расположенные на досках объявлений, форумах, блогах, «фермах» и сайтах, расположенных на бесплатных хостингах.
Еще более загадочен алгоритм Rambler. Предполагают, что Rambler большой вес придает собственному рейтингу, а также, возможно, использует некий фильтр ссылок для оценки их количества и даты появления. Помимо этого, данный поисковик «не любит», когда количество ссылок на сайт вдруг резко увеличивается, правомерно подозревая, что имеет дело с «незаконной» накруткой.
Что касается первооснователя принципа цитируемости Google, то недавно один из его разработчиков признался, что фактор Page Rank при ранжировании страниц учитывается все меньше и меньше, поскольку в настоящее время добавились сотни других критериев. В том числе оценка текстов ссылок и текстов сайтов. Сотни критериев упомянуты, скорее всего, чтобы окончательно деморализовать оптимизаторов и отбить у них всякую охоту искусственно продвигать свои сайты. На самом деле, как отметил в одном из своих интервью основатель и технический директор компании «Яндекс» Илья Сегалович – поисковые машины, разрабатывая свои алгоритмы, учитывают не так много факторов, как думают оптимизаторы. Однако «вес» каждого параметра постоянно меняется.

 Теги:
Теги:
