
Сегодня практически каждый понимает, что нет таких данных, которые было бы невозможно получить. Чтобы получить данные по сайту, используются бесплатные инструменты или тратятся огромные суммы денег на платные инструменты, чтобы получить еще больше информации. Неважно какую информацию вы ищите, вы точно ее найдете и вопрос лишь в том — бесплатно или за деньги.
У всех инструментов есть кое-что общее — это кнопка «Экспорт». Возможно, это самое важное свойство всех инструментов. Сэкспортировав данные в Excel, специалист может сортировать и фильтровать их так, как ему нужно. Большинство из нас регулярно пользуется Excel, но только его стандартными функциями. Однако Excel может гораздо больше!
о наиболее распространенных приемах обработки статистических данных. И самое главное — вам не придется их запоминать, все они встроены в Excel.
Статистика — это сбор, анализ и интерпретация данных. Она помогает в тех ситуациях, когда принятию решения мешает некоторая неопределенность. Используя статистику, мы избежим неопределенность и получим действенный анализ.
В статистике можно выделить два главных направления: описательная статистика и логически выведенная статистика.
Описательная (дескриптивная) статистика используется в том случае, когда вам известны все значения в наборе данных. Например, вы задаете 1000 респондентов вопрос, любят ли они апельсины, и предоставляете им два варианта ответа: Да и Нет. Затем собираете данные и выясняете, что 900 человек ответили Да и 100 — Нет. Пропорция будет следующей: 90% составил ответ Да и 10% — ответ Нет. Достаточно легко, не правда ли?
Но как быть в том случае, когда у нас нет всех данных?
В случае когда у вас только часть данных на помощь придет логически выведенная статистика. Она используется тогда, когда вы знаете только небольшую часть всех данных и вам необходимо сделать предположение о всем объеме данных.
Давайте предположим, что вы хотите рассчитать количество просмотров email за последние два года, но вы располагаете данными только за последние шесть месяцев. Предположим, что из 1000 email-адресов письма открыли только 200 получателей, значит остальные 800 — не открывали. Следовательно мы имеем соотношение 20% открывших к 80% неоткрывших. Эти данные верны для периода в шесть месяцев, но они также могут быть верны и для периода в два года. Логически выведенная статистика поможет нам понять, насколько верно наше предположение.
Доля открытых писем может составлять 20%, а может немного отличаться. Допустим, она варьируется +/-3%, тогда доля открытых писем будет составлять от 17% до 23%. Но насколько мы уверены в этих данных? Кроме того, какой процент случайной выборки из всего набора данных будет находиться в диапазоне от 17% −23%?
В статистике считается приемлемым уровень достоверности в 95%. Это означает, что 95% выборочных данных, взятых из всего набора данных, будет соответствовать 17-23%, оставшиеся 5% будут либо выше 23%, либо ниже 17%. Но мы уверены в том, что для 95% доля открытых писем составляет 20% +/- 3%.
Термин данные (data) предполагает любую величину, обозначающую объект или событие, например, посетители, исследования, письма.
Термин набор данных (data set) состоит из двух компонентов: Единица наблюдения (observation unit) может означать посетителей и переменные, представляющие демографические данные ваших посетителей (возраст, зарплата, образование). Совокупность (population) предполагает каждого члена вашей группы, а в веб-аналитике — всех посетителей. Предположим, посетителей 10 000.
Выборка (sample) — часть вашей совокупности, представленная на основе определенной даты или сконвертированных посетителей и т.д. В статистике наиболее ценной является случайная выборка (random sample).
Распределение данных (data distribution) определяется частотой, согласно которой представлены значения в наборе данных. Представив частоту на графике с диапазоном значений на горизонтальной оси и частотой по вертикальной оси, мы получим кривую распределения. Наиболее распространенным является нормальное распределение или колоколообразная кривая.
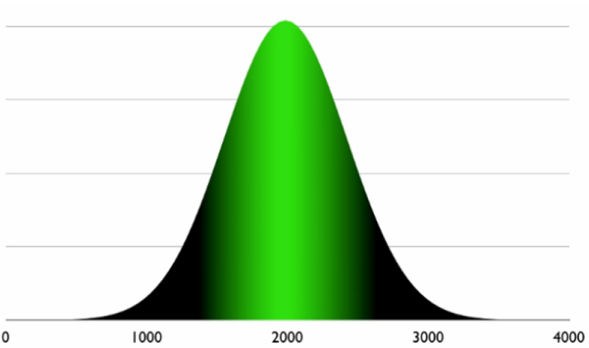
Самый простой способ понять это — представить на количестве посетителей веб-сайта. Например, в среднем ежедневное количество посещений сайта составляет 2000, иногда бывает больше — 3000 посещений или меньше — 1000.
Здесь пригодится теория вероятности (probability theory).
Вероятность означает вероятность события, которое происходит, например, при наличии 3000 посетителей в день и выражается в процентах.
Самым распространенным примером вероятности, известным многим, является подбрасывание монеты. У монеты две стороны: орел и решка. Какова вероятность того, что монета ляжет той или другой стороной? Существует две возможности, таким образом 100%/2=50%
Достаточно теории, перейдет к практике.
Excel — прекрасный инструмент, который поможет нам в работе со статистикой. Отметим, что это не лучший инструмент, но зато все знают, как им пользоваться, поэтому рассмотрим именно Excel.
Во-первых, установите надсройку Analysis ToolPack.
Откройте Excel, перейдите в Опции -> Add-ins->внизу списка вы найдёте
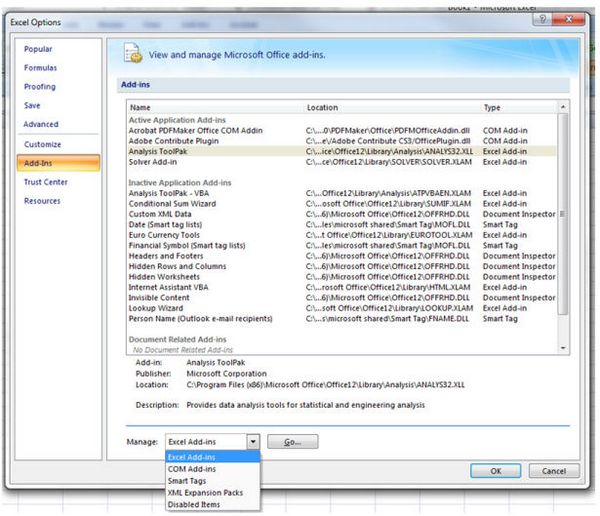
Нажимайте Go ->выберите Analysis ToolPack->и нажимайте OK.
Теперь в панеле выберите опцию Данные и найдите там Анализ данных.

Инструмент Анализ данных может предоставить вам невероятную статистическую информацию, но давайте начнем с чего-нибудь попроще.
Среднее, Медиана и Мода
Среднее (mean) это статистическое значение среднего значения, например, средним для 4,5,6 будет 5. Как рассчитать среднее значение в Excel? =average(число1,число2 и т.д.)
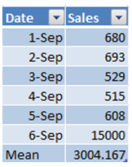
Mean=AVERAGE(AC16:AC21)
Путем вычисления среднего мы определяем, сколько мы продали в среднем. Эта информация полезна, если нет экстремальных значений (или выбросов). Почему?
Например, мы продали в среднем товаров на $3000, но на самом деле нам повезло, т.к. 6 сентября покупатели потратили больше. В предыдущие шесть дней товара было куплено в среднем лишь на $618. Исключив крайние значения от среднего, можно получить более репрезентативные даные.
Медиана (median) это значение, которое делит набор данных на две равные части. Например, для набора данных 224, 298, 304 медианой является — 298. Для того чтобы вычислить среднее для большого набора данных, можно использовать следующую формулу =MEDIAN(224,298,304).
Когда может пригодиться медиана? Медиана полезна, когда у вас есть неравномерное распределение, например, цена ваших конфет варьируется от $3 до $15 за упаковку, но также у вас есть очень дорогие конфеты за $100, которые покупают редко. В конце месяца вы делаете отчет, и вы видите, что вы продали в основном дешевые конфеты и только пару упаковок за $100. В этом случае вам будет полезен расчет медианы.
Самый простой способ понять, когда лучше использовать медиану и среднее, это построение гистограммы. Если ваша гистограмма сильно смещена до экстримальных значений, значит нужно рассчитывать медиану.

Мода (mode) самое распространенное значение, например, мода для: 4,6,7,7,7,7,9,10 это 7.
Рассчитать моду в Excel вы можете с помощью формулы =MODE(4,6,7,7,7,7,9,10).
Но имейте в виду, что Excel выдает за моду наименьшее значение из возможных. Например, вы рассчитываете моду для следующего набора данных: 2,2,2,4,5,6,7,7,7,8,9, сразу отметим, что здесь две моды — 2 и 7, но Excel покажет вам только наименьшее значение — 2.
Когда можно использовать функцию моды? Расчет моды полезен только для целых чисел, например 1, 2 и 3. И нежелателен для дробных чисел, таких как 1,744; 2,443; 3,323, т.к. числа могут дублироваться.
Гистограммы
Предположим, недавно в вашем блоге была опубликована сотня гостевых постов, некоторые из них хорошего качества, другие не очень. Возможно, вы захотели узнать, какие из постов получили по 10, 20, 30 обратных ссылок или вам интересны твиты, лайки, расшаривания, а может и просто посещения.
Мы разделили все это на группы с помощью графического представления данных под названием гистограмма. Виргил Гик (Virgil Ghic) приводит пример с посещениями и постами, как один из менее сложных. Он настроил свой аккаунт в Google Analytics следующим образом: у него есть профиль, в который собирается статистика только по его блогу, ничего больше. Если у вас нет такого же профиля, тогда вы можете использовать сегменты.
Это несложно.

Далее идем в экспорт ->CSV
Открываем Excel и создаем два столбца: Целевая страница и Посещения. Также создаем список, в соответствии с которым будем категоризировать данные. В данном случае мы определяем, сколько статей имеют 100, 300, 500 и т.д. посещений.
Данные -> Анализ данных->Гистограммы->OK
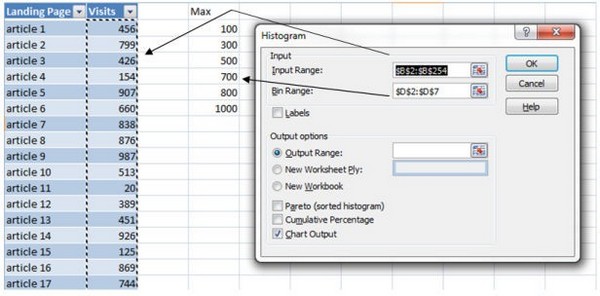
- Входной интервал (input range) будет столбец с посещениями.
- Интервал карманов (bin range) — это группы.
- Выходной интервал (output range), кликните на ячейку, где вы хотите создать гистограмму.
- Проверьте график выхода (chart output).
- Нажимаем OK.
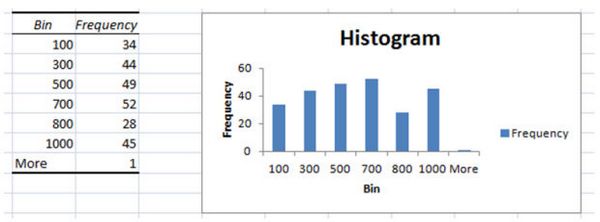
Вы получили гистограмму, которая отражает количество статей, сгруппированных по посещениям. Чтобы лучше разобраться в гистограмме, нужно кликнуть на любую ячейку в столбцах Bin и Frequency и отфильтровать частоту от меньшего к большему.
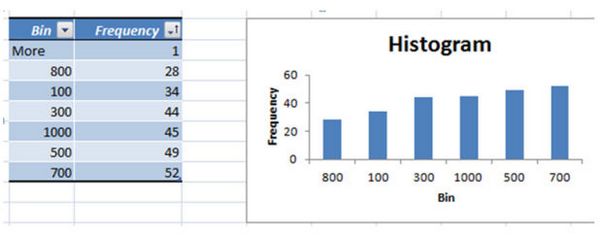
Анализировать данные теперь еще проще. Возвращаемся и фильтруем все статьи от меньшего или равного 100 посещениям (Визиты, выпадающее меню->Числовые фильтры->Между...0-100->Ok) в прошлом месяце и обновляем.
Источники посещений
Насколько значим данный отчет для вас?
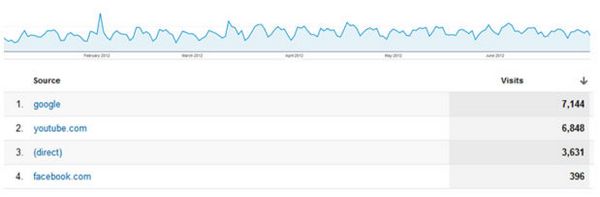
Он достаточно хорош, но не более того. Мы можем проанализировать рост и снижение посещений, но ... какова доля посещений с YouTube в общей статистике посещений за февраль? Конечно, можно разбираться, но это дополнительная работа, и это очень неудобно, когда этот вопрос вам задает клиент по телефону. Чтобы ваши графики были максимально полезны, создавайте описательные отчеты.
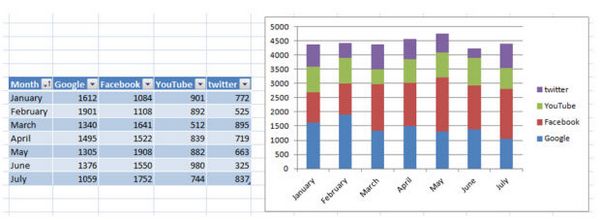
В вышеупомянутом отчете просто разобраться, сложнее его создать. Но зато он вам очень пригодится.
Что мы видим в мае: доля переходов с Facebook в общей статистике посещений больше обычного. Почему? Возможно, в мае рекламная кампания оказалась более эффективной, чем в другие месяцы, это и привело к росту трафика с Facebook. Если дело в рекламной кампании, давайте повторим ее.
Однако правильней будет провести хи-квадрат тест (Chi-Square Test), который позволит нам понять была ли это счастливая случайность или эффективная маркетинговая кампания.
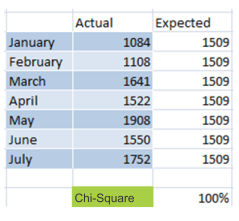
Фактический столбец — количество посещений, Ожидаемый столбец — среднее из «фактического» столбца. Формула хи-квадрат теста следующая: =1-CHITEST(N10:N16,O10:O16), где N10:N16 — это значения из Актуального столбца, а O10:O16 — значения из Ожидаемого.
Результат в 100% является уровнем достоверности, свидетельствующий о вероятности того, что рост посещений с Facebook является результатом маркетинговых кампаний.
Создавая метрики, помните, они должны быть максимально понятными и релевантными вашей бизнес-модели.
В вы найдете еще один пример использования хи-квадрат теста.
Скользящее среднее (moving average) и линейная регрессия (linear regression) для прогнозирования
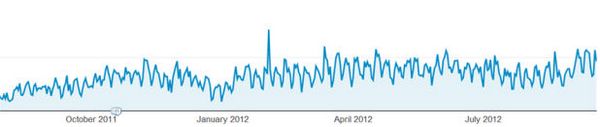
Мы часто встречаем такие графики, как расположенный выше. На них могут быть представлены продажи, посещения и т.д. И они всегда выглядят именно так: прямая, идущая вверх-вниз. В такой картине данных присутствует много шума, который мы хотим сгладить для лучшего понимания данных.
Решением является скользящее среднее! Данный метод обычно используется трейдерами для прогнозирования цен акций, которые сегодня могут взлететь вверх, а уже завтра обвалиться.
Давайте разберемся, как мы можем использовать данный метод.
Шаг 1:
Экспортируйте в Excel число посещений/продаж за долгий период времени, например, один-два года.
Шаг 2:
Данные-> Анализ данных -> Скользящее среднее ->OK
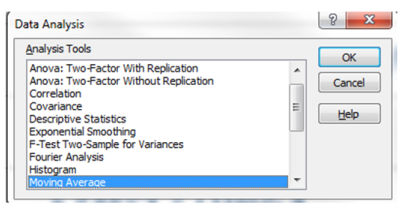
Входной интервал — это столбец с числом посещений.
Интервал — это количество дней для которых вычисляется среднее. Вам нужно создать одно скользящее среднее с большим числом, например, 30 и одно с меньшим числом, например, 7.
Выходной интервал — это столбец справа от столбца посещений.
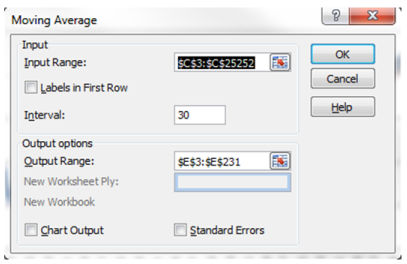
Повторите данные шаги для интервала в 7 дней.
Теперь ваши данные выглядят примерно так:
Если вы выберете все столбцы и построите линейный график, вы получите следующее:
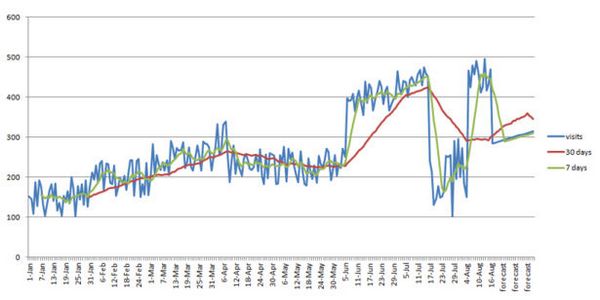
В таком представлении данных меньше шума, их легче анализировать и можно увидеть некоторые тренды. Зеленая линия визуально немного облегчает график, но она реагирует на почти каждое крупное событие. Тогда как красная линия является более стабильной, она отражает реальный тренд.
В конце линейного графика вы увидите такие значения, как Прогноз. Это прогнозируемые данные, выведенные на основе предыдущих трендов.
В Excel есть два способа создать линейную регрессию, используя формулу =FORECAST(x,known_y’s, known_x’s), где «x» означает дату, для которой вы создаете прогноз; «known_y’s» — это столбец посещений, «known_x’s» — столбец с датами. Данный метод не так уж сложен, но есть более простой способ сделать то же самое.
Выделив весь столбец посещений и потянув вниз за край, автоматически сгенерируется прогноз на следующие даты.
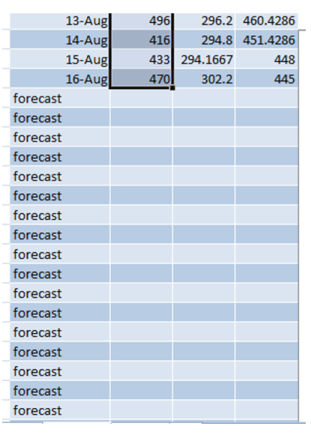
Убедитесь в том, что вы выбрали весь набор данных для того, чтобы результат был точный.
Существует теория при сравнении скользящего среднего для 7дней и 30дней. Как было сказано выше линия 7дней реагирует практически на все основные изменения, в то время как линии 30дней требуется больше времени, чтобы изменить свое направление. Как правило, когда скользящее среднее 7дней пересекает скользящее среднее 30дней, вы можете рассчитывать на существенное изменение, которое будет длиться дольше, чем день или два. Как можно увидеть выше, 6 апреля скользящее среднее 7дней пересекает скользящее среднее 30дней, число посещений снижается, у 6 июня линии снова пересекаются и тренды идут вверх. Этот метод полезен, когда вы теряете трафик и не уверены, тренд ли это или всего лишь суточные колебания.
Линия Тренда (trendline)
Те же результаты могут быть получены с помощью линии тренда в Excel: щелкните правой кнопкой мыши по движущейся линии -> выберите: Добавить линию тренда (Add Trendline).
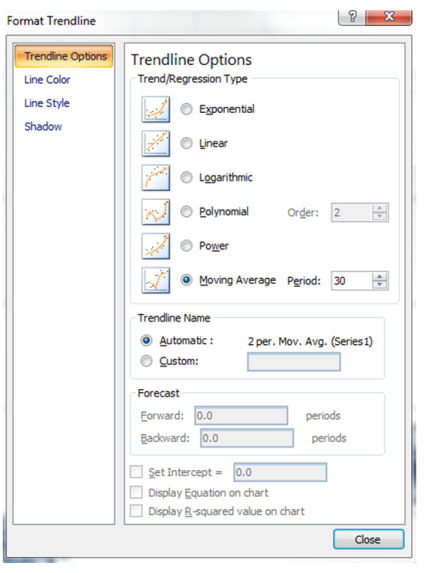
Теперь вы можете выбрать Тип Регрессии (Regression Type) и использовать функцию Прогноз. Линия тренда, возможно, наиболее полезный инструмент, помогающий разобраться почему ваш трафик/продажи растут, сокращаются или остаются неизменными.
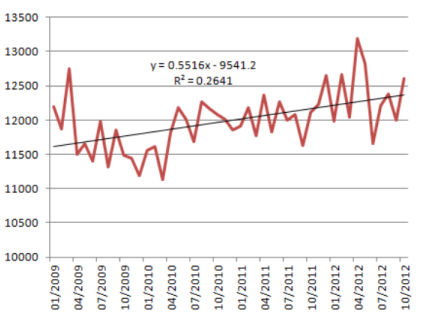
Без линейной функции мы не сможем уверенно говорить о том, что мы делаем правильно, а что нет. Добавляя линейный тренд мы видим, что наклон положительный, уравнение линии тренда объясняет, как движется наш тренд.
y=0.5516x-9541.2
X — это количество дней. Коэффициент Х — 0.5516 — положительное число. Это означает, что линия тренда идет вверх. Т.е. ежедневно мы увеличиваем количество посетителей на 0,5, это является трендом.
R^2 — это уровень точности модели. Наше число R^2 = 0,26 означает, что наша модель объясняет 26% вариаций. Проще говоря, мы уверены на 26%, что ежедневно количество посетителей увеличивается на одного.
Сезонное прогнозирование
Предположим, скоро Рождество. Прогнозирование на зимний сезон будет весьма полезно, особенно когда с этим периодом вы связываете большие надежды.
Если вы не попали под Google-фильтры Panda или Penguin и ваши продажи/посетители соответствуют сезонным тенденциям, вы можете спрогнозировать характер продаж или посещений.
Сезонное прогнозирование — это метод, который позволяем нам оценить будущие значения набора данных на основе сезонных колебаний. Сезонные наборы данных есть везде, например, магазин мороженого будет очень востребован во время летнего сезона, а сувенирный магазин может достичь максимальных продаж во время зимних праздников.
Прогнозирование данных на ближайшее будущее может быть очень полезно, особенно когда мы планируем вкладывать деньги в маркетинговые кампании для таких сезонов.
Следующий пример представляет собой базовую модель, но она может быть расширена до более сложных, чтобы отвечать вашей бизнес-модели.
Загрузите
Для удобства восприятия я разобью весь процесс на этапы. Вам нужно загрузить таблицу Excel и выполнить следующие шаги:
- Экспортируйте ваши данные; чем больше данных, тем более точным будет прогноз! Укажите даты в столбце А, а продажи в столбце В.
- Рассчитайте индекс для каждого месяца и добавьте полученные данные в столбец С.
Для расчета индекса прокрутите вниз, справа вы найдете таблицу под названием Индекс (Index). Индекс за январь 2009 рассчитывается путем деления продаж за январь 2009 г. на среднее значение продаж за весь 2009 год.
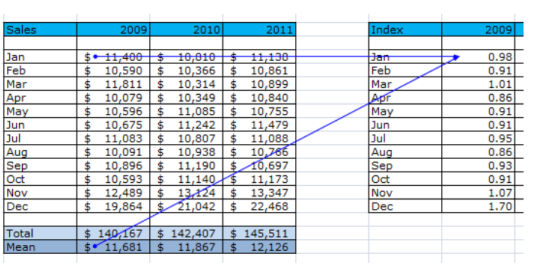
Таким же образом рассчитайте индекс для каждого месяца каждого года.
В столбце S с 38 по 51 строки мы рассчитали средний индекс для каждого месяца.
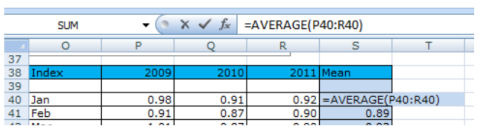
Т.к. сезонность повторяется каждые 12 месяцев, мы скопировали значения индекса в столбец C, т.к. они остаются актуальными. Вы можете заметить, что индекс января 2009 такой же как и в январе 2010 и 2011 годов.
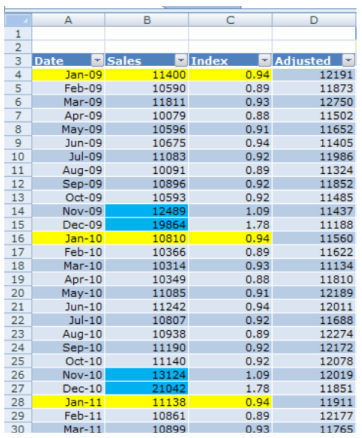
- В столбце D рассчитайте Скорректированные данные (Adjusted data) путем деления ежемесячных продаж на индекс =B10/C10.
- Выберите значения из столбцов A, B и D и постройте линейный график.
- Выберите скорректированную линию (в моем случае это красная линия) и добавьте линейный тренд, проверьте окошко «Показать уравнение на графике».
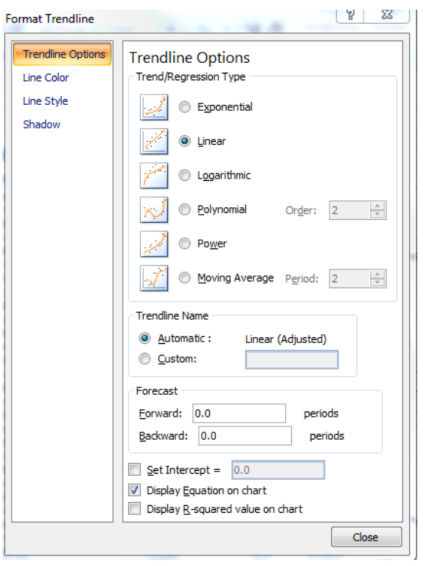
- Рассчитайте несезонные значения для прошлого периода путем умножения ежемесячных продаж на коэффициент из уравнения линии тренда и добавьте константу из уравнения (столбец Е).
После создания линии тренда и представления Уравнения на графике, мы принимаем во внимание Коэффициент — число, которое умножается на X, и константу — число, которое, как правило, является отрицательным.
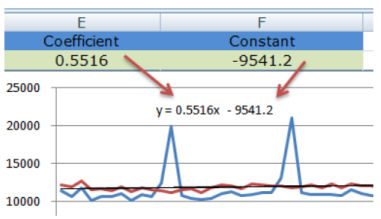
Проставляем коэффициент в ячейку E2, а Константу — в ячейку F2.
- Рассчитайте Сезонные значения для прошлого периода путем умножения индекса (столбец С) на ранее рассчитанные данные (столбец Е).
- Рассчитайте средний процент ошибки (MPE — mean percentage error) путем деления продаж на Сезонные значения для прошлого периода минус 1 (=B10/F10-1).
- Рассчитайте средний абсолютный процент ошибки (MAPE — mean adjusted percentage error) путем возведения в квадрат данные в стобце MPE (=G10^2).

В моих ячейках F50 и F51 представлены спрогнизованные данные для ноября 2012 и декабря 2012. Ячейка H52 демонстрирует погрешность.
С помощью данного метода мы можем определить, что в декабре 2012 мы заработаем $22,022 ± 3.11%. Теперь идем к боссу и рассказываем о своих предположениях.
Стандартное отклонение
Стандартное отклонение (standard deviation) говорит о том, насколько наши значения отклоняться от среднего значения, мы можем назвать его уровнем доверия. Например, у вас есть данные по продажам за месяц и данные по ежедневным продажам, причем каждый день объем продаж разный. Вы можете использовать стандартное отклонение чтобы рассчитать, насколько вы отклонились от среднемесячного показателя.
Вот две формулы Стандартного отклонения в Excel, которые вы можете использовать
=stdev — когда у вас есть выборочные данные -> Авинаш Кошик подробно рассказывает, как
или
=stdevp — когда у вас полная совокупность данных, т.е. когда вы анализируете каждого посетителя. Я предпочитаю именно =stdev, потому что бывают случаи, когда код отслеживания JS не работает.
Давайте посмотрим, как мы можем применить стандартное отклонение в нашей повседневной жизни.
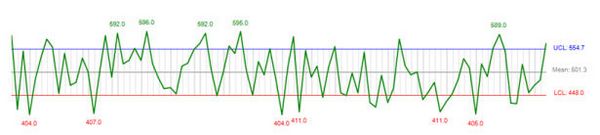
Используя стандартное отклонение в Excel, данные можно представить более наглядным и понятным образом. Как вы видеть на графике выше, средняя ежедневная посещаемость равна 501 со стандартным отклонением 53. Но самое главное на таком графике вы видите, где вы превысили свои обычные показатели. Это позволит выделить те маркетинговые кампании, которые привели к такому всплеску, и применить/проверить их еще раз.
Для работы используйте данную ссылку: http://blog.instantcognition.com/wp-content/uploads/2007/01/controllimits_final.xls
Корреляция
Корреляция — это статистическая взаимосвязь двух или нескольких (случайных) переменных. Типичным примером корреляции в веб-аналитики может быть количество посетителей и количество продаж. Чем больше у вас целевых посетителей, тем больше будет продаж. У доктора Пита (Dr Pete) есть хорошая , посвященная корреляции vs. причинности.
В Excel мы используем следующую формулу для определения корреляции:
=correl(x,y)
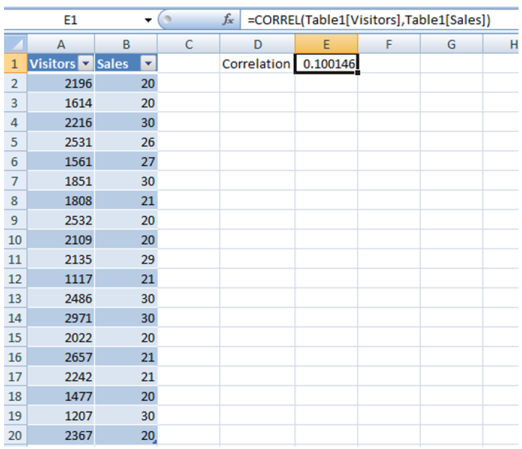
Как вы видит на картинке выше, корреляция между Посещениями и Продажами равна 0.1. Что это значит?
- от 0 до 0,3 считается слабой корреляцией
- от 0.3 до 0,7 — нормальная
- более 0,7 — сильная
Заключение следующее: ежедневные посещения не влияют на ежедневные продажи, что также означает, что посетители, которых вы привлекли, не являются целевыми. При принятии решения полагайтесь на ваше деловое чутье, но не игнорируйте корреляцию в 0,1.
Если вы хотите определить корреляцию между тремя и более переменными, используйте функцию корреляции в разделе Анализ данных.
Данные->Анализ данных->Корреляция
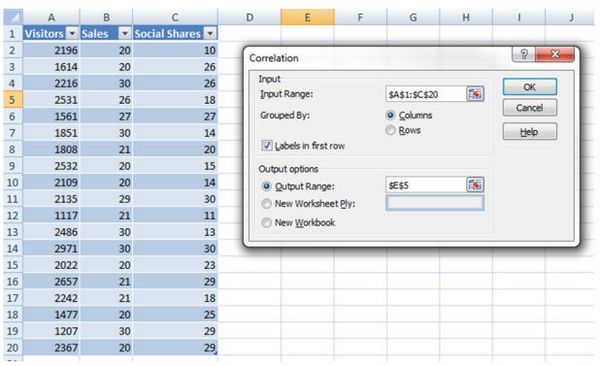
Ваш результат будет похож на один из этих:
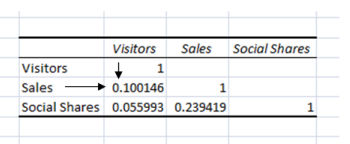
Здесь мы видим, что ни один из элементов не коррелируют друг с другом:
- Продажи и посетители = корреляция 0,1.
- Продажи и расшаривания = корреляция 0,23.
- Описательная статистика для быстрого анализа.
Теперь у вас есть довольно хорошее представление о среднем, стандартных отклонениях и т.д., но расчет каждого статистического элемента требует дополнительного времени. В разделе Анализ данных вы найдете краткий обзор наиболее распространенных элементов.
- Данные->Анализ данных-> Описательная статистика.
- Входной интервал — выбираем данные для анализа.
- Выходной интервал — выбираем ячейку, где отобразится таблица.
- Проверяем Сводную статистику.
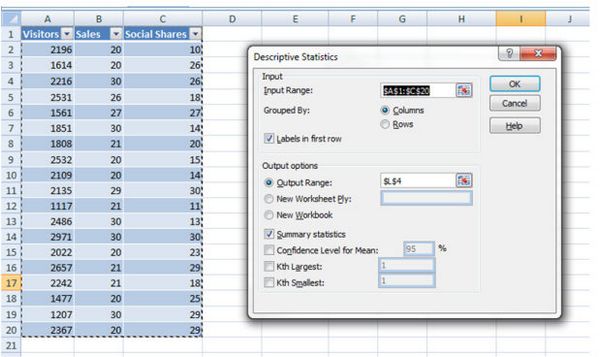
Достаточно хороший результат:
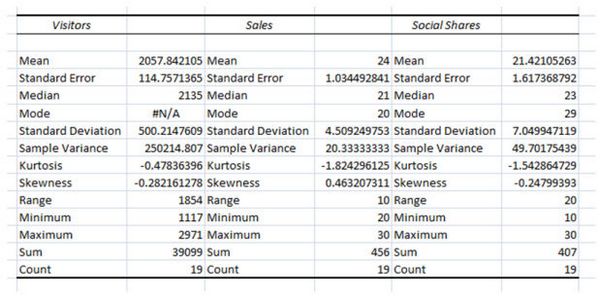
Нам осталось разобраться с тем, что такое Эксцесс (kurtosis) и Асимметрия (skewness).
Эксцесс — это мера остроты пика распределения случайной величины, как далеко пик кривой находится от среднего значения. Чем выше значение эксцесса, тем острее пики по бокам. В нашем случае эксцесс является очень низким, это означает, что значения распределены равномерно.
Асимметрия показывает, насколько искажены ваши данные — негативно или позитивно, по сравнению с нормальным распределением. Теперь представим асимметрию более наглядно:
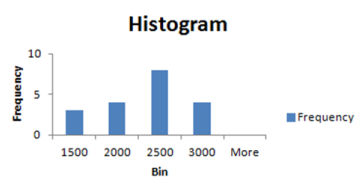
Асимметрия: −0.28 (распределение, скорее всего, ориентировано на более высоких значений 2500 и 3000).
Эксцесс: −0.47 (небольшое пиковое отклонение от центра).
Все эти методы можно использовать при анализе данных. Самой большой сложностью со статистическими данными и Excel является возможность применения этих методов в самых различных ситуациях, не ограничиваясь посещениями или продажами. Отличный пример использования нескольких статистических подходов представил Том Энтони в своем посте об инструменте для определения ссылочного профиля ().
Приведенные выше примеры являются лишь малой частью того, что можно сделать с помощью статистики и Excel. Если вы используете другие методы, поделитесь ими в комментариях.

 Теги:
Теги:






