В предыдущей части мастер-класса мы познакомились с основами текстового ранжирования, а точнее с той частью, которая происходит непосредственно перед оценкой текстового веса документа.
Теперь рассмотрим основные текстовые факторы, влияющие на релевантность документа.
2. Основная часть
Итак, начнем с основ информационного поиска – формулы TF*IDF.
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова ti в пределах отдельного документа:
где ni есть число рассматриваемых употреблений слова, а в знаменателе общее число словоупотреблений.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Таким образом, понижается вес широкоиспользуемых слов.
где D — количество документов в корпусе;
- количество документов, в которых встречается ti, когда
Конечно же, Яндекс для оценки релевантности документа использует видоизмененную формулу. Сделаем сразу оговорку, что у нас речь пойдет об относительной релевантности, т.е. релевантности нескольких документов одному запросу, таким образом, величина IDF просто-напросто сократится при расчетах.
В общем виде формула имеет вид:
т.е. текстовая релевантность (W) рассчитывается как отношение количества найденных ключевых слов к «тошноте». «Тошнота» рассчитывается как квадратный корень из частоты самого часто встречаемого слова в документе.
Если ЧСЧВС меньше семи, то тогда:
Если «тошнота» превышает некий порог (для различных слов он различен, но примерно это интервал от 20 до 25), то Яндекс начинает искусственно занижать вес документа.
Почему «тошнота»? Это определение ввел в речевой обиход оптимизаторов Миныч, после этого определение так и прижилось.
Итак, из формулы мы видим, что в Яндексе нет такого понятия как «плотность ключевого слова», т.е. объем всего текста не учитывается. Это подтверждает эксперимент «Зависимость релевантности страницы от количества нерелевантных пассажей».
При расчете «тошноты» документа учитываются и стоп-слова. (См. эксперимент «Учет стоп-слов при расчете тошноты»).
Уточним далее формулу.
Не все ключевые слова вносят свой вклад в релевантность документа, а только те, которые попали в релевантные пассажи. Если запрос однословный, т.е. ключевой слово одно, то тогда любой пассаж, содержащий это слово, будет релевантным. Если у нас - ключевая фраза из нескольких слов, то при расчете релевантности будут учитываться только те пассажи, которые прошли кворум.
При этом если в одном пассаже ключевое слово будет повторять несколько раз (более 4), то это негативно отразиться на релевантности документа.
Углубляемся дальше. Пассаж пассажу рознь. Во-первых, пассаж может принадлежать различным зонам документа:
o title
o description
o keywords
o body
Во-вторых, пассаж, относящийся к body, может иметь различное форматирование – например, пассаж может быть заголовком < h1>. Также пассаж может быть включен в теги < script>, < noindex> - в этом случае пассаж проиндексирован не будет.
На seonews.ru уже публиковалось несколько экспериментов, посвященных изучению влияния принадлежности пассажа к определенной зоне документа. В результате были сделаны следующие выводы:
1. Description и keywords сайта не влияют на релевантность. При этом keywords вообще не индексируется.
2. Заголовки < h1>…< h6> немного повышают релевантность документа.
3. Title влияет на релевантность (Однако надо помнить, что из title индексируется только 15 первых слов!).
Кроме учета принадлежности пассажа, также учитывается е еще несколько факторов.
Расхожее мнение о том, что на релевантность влияет форматирование ключевых словом при помощи тегов , , и т.д. сейчас уже неактуально. Все это осталось в прошлом.
Гораздо важнее точность вхождения ключевой фразы в документ – точность с точки зрения морфологии и точность с точки зрения словопозиций.
В подтверждении несколько примеров.
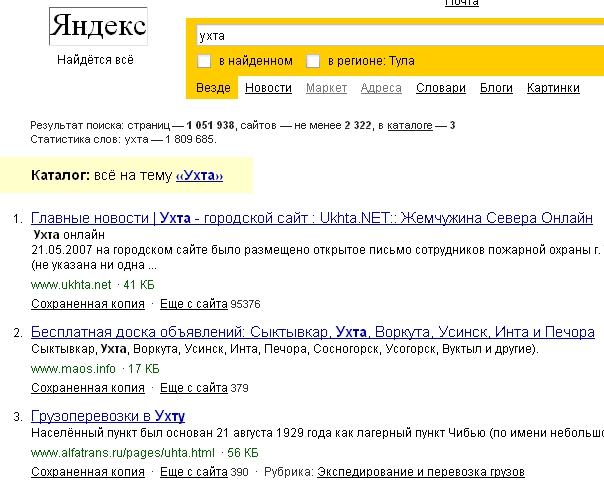
Сделаем запрос «Ухта». Получим следующую выдачу:
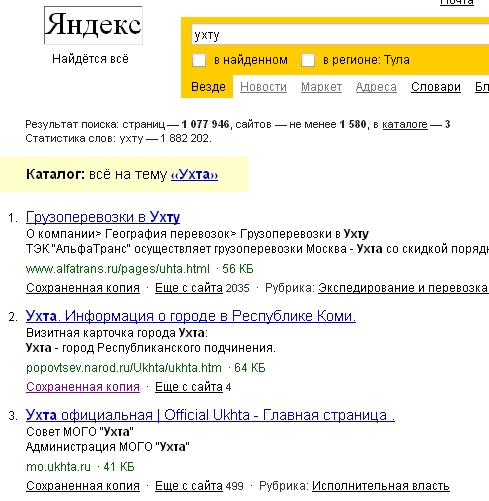
Теперь изменим окончание и зададим запрос «Ухту». Мы видим и изменение в выдаче. На первом месте появился сайт, который имеет точное совпадение с запросом.
Аналогично можно поэкспериментировать со словопозициями.
Например, для запросов «Майкл Джаггер» и «Майкл &/(-1 5) Джаггер» выдача будет отличаться. Напомним, что конструкция «Майкл &/(-1 5) Джаггер» означает, что слово Джаггер должно находиться в районе 1 слова слева или 5 слов справа от слова «Майкл».
Оптимальной позицией слова «Джаггер» относительно слова «Майкл» будет позиция через одно слов справа, т.к. (5+(-1))/2=2. Эта формула для расчета оптимальной позиции в свое время тоже была предложена Минычем.
3. Рекомендации по оптимизации текста
Конечно, количественный расчет текстовой релевантности дело интересное и нужное, но для практических целей вполне подойдет ряд рекомендаций, соблюдая которые, вы напишете хороший (с т.зр. Яндекса) контент для сайта.
Главный принцип, которому нужно следовать – естественность текста. Не надо перегружать содержимое сайта ключевыми словами, тегами форматирования и прочим. Все должно быть в меру.
Друзья, теперь вы можете поддержать SEOnews https://pay.cloudtips.ru/p/8828f772
Ваши донаты помогут нам развивать издание и дальше радовать вас полезным контентом.
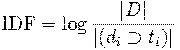
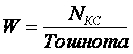


 Теги:
Теги: