Данный мастер-класс, посвящен одной из составляющей процесса продвижения сайтов – текстовой оптимизации. Однако сразу оговоримся – это будет не руководство к действию, а больше руководство к размышлению и экспериментаторству. Вы не узнаете из прочитанного, сколько нужно раз употребить ключевое слово в тексте из 500 символов, но зато вы узнаете, как Яндекс учитывает эти самые ключевые слова, их частоту и форматирование.
Материал сделан на основе теоретических сведений, почерпнутых из различных источников, в том числе и иностранных публикаций. Также эти сведения проверялись экспериментальным путем.
2. Принцип поиска в Яндексе
Прежде всего, стоит разобраться, как работает Яндекс на этапе обработки запроса пользователя. Об этом лучше всего рассказано у Миныча.
"Поиск" документов Яндексом происходит поэтапно:
- Сначала запрос анализируется, и на него накладываются контекстные ограничения по умолчанию ("переколдовка" запроса)
- Далее происходит отбор документов с найденными словами и с частично найденными словами (фильтрация по кворуму)
- Далее происходит ранжирование отобранных документов.
Итак, рассмотрим эти этапы, так как для понимания принципов текстового ранжирования это обязательно знать.
Переколдовка запроса
Слова, заданные в поисковом запросе преобразуются – на них накладываются контекстные ограничения. Преобразованная фраза в общем случае выглядит следующим образом:
(слово1: вес слова1 расстояние1 слово2: вес слова2 … и т.д.) // мягкость
- слово1, слово2 и т.д. это слова из поискового запроса
- вес слова1 – все слова, вычисляется исходя из частоты вхождений слова в коллекцию документов Яндекса. Для редких слов вес "обрезается" на большом значении и одинаков для всех редких слов. На сегодняшний момент (07.06.2007) эта величина составляет 1 819 103 916.
- расстояние1 – расстояние, в пределах которого должны встречаться слово1 и слово2.
& означает, что слова должны встречаться в одном пассаже (что такое пассаж – чуть позже);
&/(-x y) означает, что слово2 должно находить в пределах х слов считая налево от слова1 или y слов направо от слова1;
Двойное && между словами означает, что эти два слова могут находиться в любом месте документа;
Конструкция &&/(-7+7) говорит, что слово2 должны быть в тексте не далее чем на плюс-минус семь пассажей от слова1.
Например, для запроса «сравнение профилей алюминий» получим:
Да, кстати, чтобы узнать переколдовку для фразы требуется скопировать из результатов выдачи по этому запросу адрес ссылки «сохраненная копия» и затем декодировать ее. Искомая переколдовка будет идти после параметра reqtext.
Иногда исходный запрос так переколдовывается, что некоторые слова вообще выпадают из поиска, а некоторые слова добавляются к запросу. Например, запрос «что такое seo» -
Здесь мы видим, что наравне с фразой «что такое seo» будут искаться фразы «seo это», «seo означает» «seo аббревиатура расшифровывается».
Теперь необходимо сделать пояснения относительно слова «пассаж».
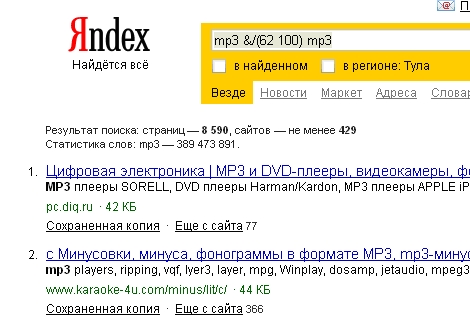
Пассаж – это часть текста, разделение которого происходит с помощью разделителей пассажей, которыми могут являться различные теги и знаки препинания. Принято считать, что максимальная длина пассажа равна 64 словам. Проверить максимальную длину пассажа довольно легко: нужно последовательно задавать ряд запросов в виде слово1 &/(60 100) слово2, увеличивая каждый раз значение левой границы ограничений, т.е. &/(60 100) --> &/(61 100) --> &/(62 100). Например, для запроса mp3 &/(62 100) mp3 получим:
Для запроса mp3 &/(63 100) mp3 в выдаче не будет ни одного сайта. Из этого можно сделать вывод, что максимальная длина пассажа – 64 слова. Проверка для других запросов показывает аналогичные результаты.
Какие теги являются разделителями пассажей, также легко проверить с помощью простых запросов. Сначала нужно найти подходящую страничку для проверки. На странице есть следующий код:
«Сайт» - адрес экспериментально сайта
«стоп-слова» - количество самого часто встречаемого стоп-слова в документе
Проверим, является ли тег
разделителем. Введем запрос:
«экспериментально & количество»
Как видно, ничего не найдено. Т.е. слова «экспериментально» и «количество» находятся в разных пассажах.
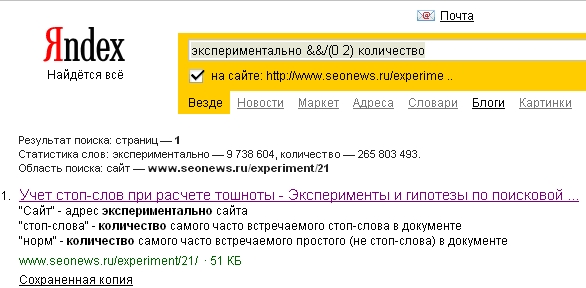
Введем запрос «экспериментально &&/(0 2) количество». Мы увидим, что страничка будет найдена. При этом в сниппете отчетливо видны 3 пассажа. То что пассаж заканчивается видно по отсутствию “…”.
Сразу скажем, что знаки препинания: «точка», «многоточие», «двоеточие», восклицательный знак», «вопросительный знак» являются разделителями пассажей только если после них находится слово с большой буквы.
Фильтрация по кворуму
Наверное, вы обращали внимание, что при поиске по запросу из 4-5 слов и более найденные документы содержат не все искомые слова. Это объясняется существованием кворума - такой комбинации слов из запроса, при котором заданная комбинация считается достаточной, для того чтобы документ считался "найденным" при наличии в нем этой комбинации слов из запроса (с учетом контекстных ограничений). Например, вы искали «как выглядит птенец кукушки фото». Кворумом здесь скорее всего будет комбинация слов «как выглядит птенец кукушки», так как слово «фото» не присутствует на сайтах в выдаче.
Получается, если бы не существовало кворума, по таким вот длинным запросам пользователю вообще бы ничего не выдавалось.
Кворум для фразы, на самом деле, считается строго по формуле.
Формула была озвучена еще в статье Сегаловича и Маслова и уже далее автором проверена для двухсловных и трехсловных запросов. Точность формулы +/- 100 IDF.
Поясним формулу на примере трехсловного запроса. «Переколдованный» он выглядит следующим образом:
Данные три слова в одном предложении не встретятся, поэтому логично предположить, что Яндекс выведет в результатах поиска 0 документов. Однако как уже упоминалось, специально для таких случаев у Яндекса существует понятие кворума.
На мой взгляд, логика ввода кворума следующая. Предполагая, что некоторые слова запроса достаточно часто встречаются в Интернете и не несут полезной информации для пользователя, Яндекс при поиске не учитывает эти слова из запроса при условии, что оставшиеся слова пройдут кворум (т.е. окажутся достаточно весомыми и контрастными на фоне «неинформативных» слов).
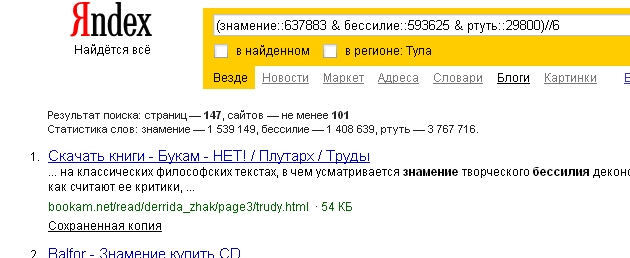
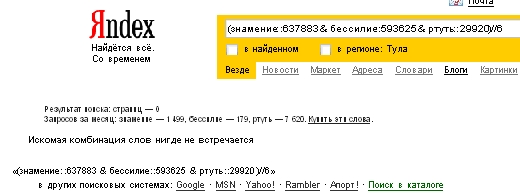
В нашем примере слово «ртуть» может оказаться «неинформативным» словом, т.к. имеет значительно меньший вес по сравнению с другими словами. Посмотрим, пройдет ли кворум вхождение, содержащее только слова «знамение» и «бессилие», чтобы документ, содержащий такое вхождение, попал в результаты выдачи. Посчитаем по формуле:
Получим: (316,0681752070) > (316,0309236502) - т.е. кворум пройден. См. рисунок 1.
Если мы увеличим вес слова «ртуть», подняв таким образом его информативность, то получим:
Видим, что пассажу, содержащему только слова «знамение» и «бессилие», не удается пройти кворум. Соответственно, в выдаче нет документов.
Ранжирование отобранных (прошедших кворум) документов
Далее происходит ранжирование прошедших кворум документов. Об этом мы поговорим в следующем мастер-классе.
3. Выводы
Итак, мы познакомились с основами текстового ранжирования, а точнее с той частью, которая происходит непосредственно перед оценкой текстового веса документа. Далее мы рассмотрим основные факторы, влияющие на вес.
Попробуем также прокомментировать статью «Яндекс на РОМИП-2004. Некоторые аспекты полнотекстового поиска и ранжирования в Яндекс». Рассмотрим в совокупности уже проведенные и опубликованные на m.seonews.ru эксперименты по текстовому ранжированию, а также озвучим планы новых экспериментов.
Друзья, теперь вы можете поддержать SEOnews https://pay.cloudtips.ru/p/8828f772
Ваши донаты помогут нам развивать издание и дальше радовать вас полезным контентом.




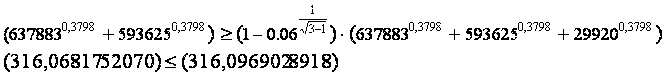


 Теги:
Теги: