 В докладе «Аффилирование, или борьба с монополизацией поисковой выдачи» Игорь Клименко, заместитель руководителя отдела продвижения AdLabs, рассказал о сайтах-аффилиатах и мерах, которые применяют Яндекс и Google для того, чтобы бороться с подобными сайтами. Аффилированные сайты создаются обычно компанией, чтобы присутствовать в выдаче на нескольких позициях по одному и тому же запросу. Таким образом компания пытается монополизировать выдачу, увеличивая вероятность клика по результатам своего сайта в разы.
В докладе «Аффилирование, или борьба с монополизацией поисковой выдачи» Игорь Клименко, заместитель руководителя отдела продвижения AdLabs, рассказал о сайтах-аффилиатах и мерах, которые применяют Яндекс и Google для того, чтобы бороться с подобными сайтами. Аффилированные сайты создаются обычно компанией, чтобы присутствовать в выдаче на нескольких позициях по одному и тому же запросу. Таким образом компания пытается монополизировать выдачу, увеличивая вероятность клика по результатам своего сайта в разы.
Яндекс и Google по-разному относятся к аффилированным сайтам. Точнее, относятся они одинаково негативно, но борются с ними по-разному. Если Яндекс замечает в выдаче несколько аффилированных сайтов, то он оставляет один, который, по его мнению, является наиболее соответствующим запросу. То есть Яндекс применяет фильтр линейно – исключает по определенному запросу. Google поступает иначе – он снижает позиции аффилированных сайтов. То есть в выдаче можно увидеть, что несколько сайтов присутствуют в выдаче по одному запросу: один высоко, другой в районе 50 позиции.
Также Яндекс высказывается против аффилированности в (п.5) объявлений Директа и Правилах показа в Маркете. Основаниями для применения фильтра аффилированных сайтов, которые распространяется как на органическую выдачу, так и на контекстные объявления, являются:
· Совпадение на сайтах значительной части ассортимента.
· Одни и те же товары предлагаются одним и тем же поставщиком (сайты принадлежат одной и той же компании).
Поисковые системы, по словам Игоря Клименко, используют следующие признаки, чтобы понять является ли сайт аффилиатом или нет:
· Одинаковые данные регистратора доменов, контактные данные при регистрации.
· Сходный дизайн и верстка.
· Одинаковые контактные данные, указанные на сайтах.
· Сходный ассортимент, одинаковые цены.
· Сходное описание разделов каталога и товары.
· Расположение подозрительных сайтов на одном хостинга.
· Жалоба конкурентов.
Проверить, попал ли сайт под аффилиат, можно по указанной схеме.
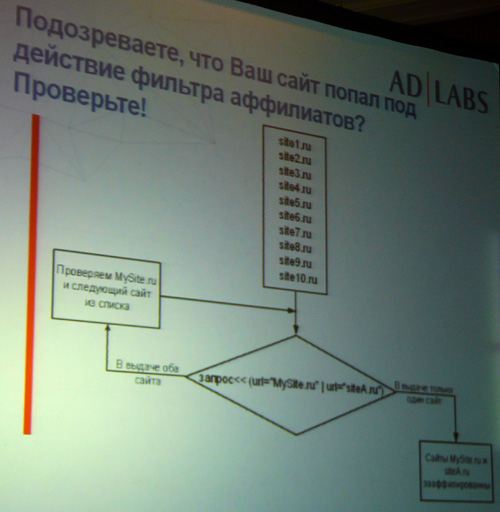
Что делать, если сайт был понижен в выдаче из-за фильтра аффилиатов:
· Определяем, с каким сайтом он зааффилирован.
· Выявляем причины.
· В случае ошибочного применения фильтра нужно обратиться в ПС.
· Если аффилиат был сделан специально, то нужно продать домен, переделать сайт, чтобы снять действие фильтра или перераспределить запросы между сайтами-аффилиатами: одни запросы «заточить» под одни сайты, другие под другие.
При удалении из выдачи сайты продолжают индексироваться. С апдейтами аффилированные сайты могут меняться: одни могут выйти вперед, другие пропасть.
 Иван Молчанов, специалист по рекламе в интернете-компании «Люкс-АР», рассказал участникам конференции о том, как поисковые системы выявляют дубликаты. Перед этим Иван сообщил, что источниками дубликатов являются:
Иван Молчанов, специалист по рекламе в интернете-компании «Люкс-АР», рассказал участникам конференции о том, как поисковые системы выявляют дубликаты. Перед этим Иван сообщил, что источниками дубликатов являются:
· различные урлы одного документа;
· преобразование документа (смена формата документа);
· редактирование документа (перестановка абзацев, предложений, форматирование текста);
· сознательная уникализация документа (спам-технологии, замена слов синонимами).
Для того, чтобы определить, является ли сайт дублем, поисковые системы применяют оффлайн- и онлайн-кластеризацию.
Под первой подразумевается вычисление хэш-функций: синтаксических, лексических, которое происходит на этапе индексации сайта. Тексты предварительно очищаются от «лишних» данных: html-разметки, тэгов, стоп-слов. Лексический алгоритм работает на основе обратного индекса поисковых систем, который выделяет локальные сигнатуры (слова в одном документе) и глобальные сигнатуры (статистика слов во всей коллекции). В процессе кластеризации отбрасываются слишком частые и слишком редкие слова. Из оставшихся составляется словарь, который описывает всю коллекцию документов.
Под онлайн-кластеризацией понимается анализ текста и ссылок, который происходит на этапе формирования выдачи. Если совпадают, например, сниппеты, то документы относятся к одному кластеру и показываются как один результат.
На примере сервиса Антиплагиат, который используется для определения «чужого» материала, Иван провел эксперимент, чтобы вывести возможную формулу создания текста, который будет считаться уникальным. Его вывод: «Если заменить каждое 4-ое слово в тексте, то можно создать уникальный текст».
Доклад Евгения Трофименко уже освещался на конференции RIW-2009.
Другие доклады конференции "Поисковая оптимизация и продвижение сайтов в Интернете 2009" вы можете в наших материалах:
VIII Ашмановская конференция стартовала
Ашмановская 2009: «За комплексным маркетингом будущее»
Ашмановская 2009: «То, что давно ждали… просили… надеялись…»
Ашмановская 2009: «Главное – выбор стратегии»
 Теги:
Теги: