12 сентября 2014 года в Москве, в event-холле «Инфопространство» состоялась очередная «Осенняя сессия по контекстной рекламе». Выступления докладчиков на мероприятии проходили в рамках «технического» и «агентского» потоков, а также потока под названием «системы автоматизации». Выступлений было очень много, поэтому мы отобрали наиболее интересные, с нашей точки зрения, доклады.
Антон предложил три способа проработки:
Первый способ заключается в том, что к высокочастотному ключевому слову добавляется большой список «минус-слов». Этот простой способ популярен среди рекламных агентств, но, по мнению Антона, релеватность и эффективность тут низки. Другими словами, показов действительно много, но переходов очень мало.
Второй подход с закавычиванием поисковых запросов, считающихся наиболее релеватными, обеспечивает хороший контекст и приводит целевых посетителей на сайт, но вот охват здесь недостаточный.
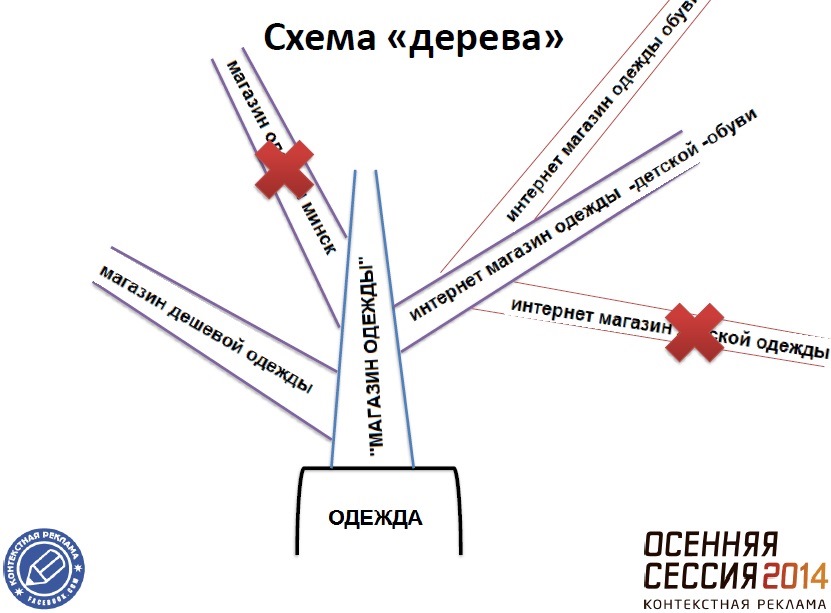
Третий способ, с разбором частотности КС, Антон назвал «смешанным» или «схемой дерева». Перед тем как перейти к его анализу, Антон продемонстрировал, как разбирать частотность КС. Для начала нужно определиться с ключевым словом, после чего отсечь вероятность нерелевантных показов.
Формула, по которой можно высчитать вероятность релевантного показа, выглядит следующим образом:
Далее эксперт более подробно разобрал «схему дерева». Её смысл заключается в том, что высокочастотное слово, имеющее несколько значений, помещается в корень дерева, то есть показывать ВЧ-запрос не стоит. От корня идёт ствол — «двухсловник», из которого произрастают ветви в виде ключевых фраз, состоящие из трех и четырех слов. Эти дополнительные слова, вместе с которыми пользователь вводит ВЧ-запрос в поисковик, Антон назвал «масками».
По мнению Антона, для создания таких схем нужна программа, работающая с ключевыми словами. Для того чтобы работа проходила корректно, при написании программного движка следует:
Антон порекомендовал следующие сервисы для сбора семантики:
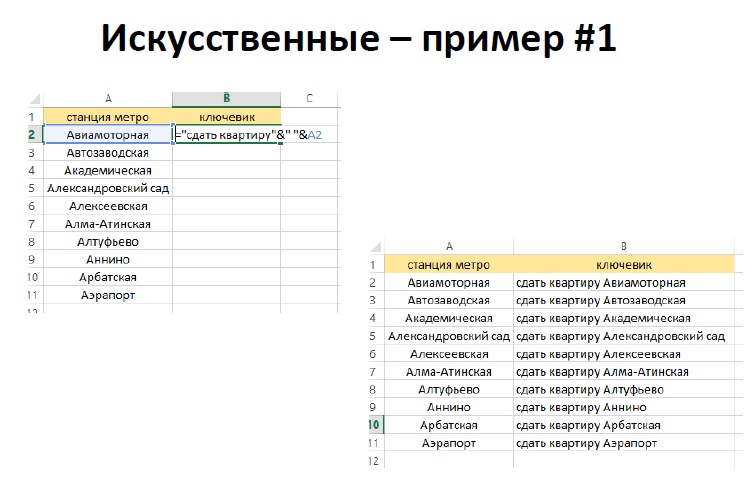
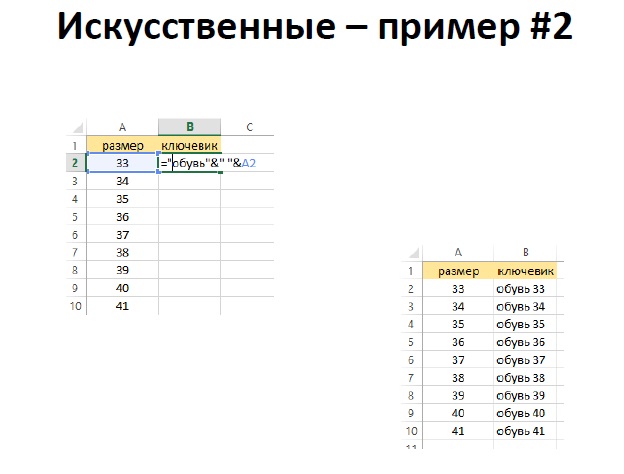
В качестве примера искусственных слов Антон Данилов привёл привязку слов:
В своем докладе Антон также рассказал о том, как лучше сравнить CTR двух объявлений при А/В-тестировании в Яндекс.Директе. Сравнивать лучше всего посредством биддинга — торга в реальном времени. Действовать здесь нужно в следующей последовательности:
В конце доклада Антон кратко напомнил основные пункты построения контекста:
Доклад Валерия был поделен на три части:
Первое, о чем рассказал эксперт, что надо делать до запуска рекламной кампании и как прогнозировать результат. Валерий приводил примеры из опыта работы NetPeak, специалисты которого начинают готовить проект со следующих действий:
Докладчик пояснил, что в NetPeak работают только через Google Tag Manager. Что касается Яндекс.Метрики, то через неё получают данные для контекстной рекламы. Метрик обязательно устанавливают две — одна резервная. Кроме этого, клиенту обязательно даются прогнозы по сезонности запросов и прочая нужная информация.
В рамках технической подготовки проекта обязательны:
Настройка целей для рекламной кампании
Далее можно переходить к подготовительным работам. К ним относятся:
В работу с аккаунтом входят:
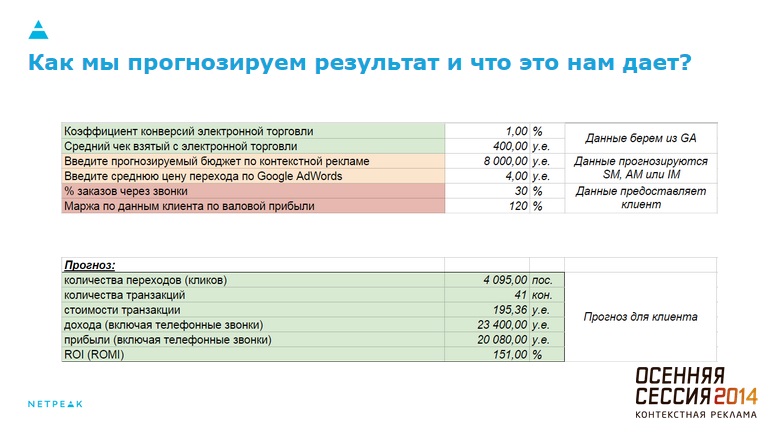
В третьей части доклада, посвященной прогнозированию, эксперт отметил, что единственно верного способа предсказать результат, нет. Тем не менее, прогнозы помогают решить такие задачи, как:
Докладчик продемонстрировал пример того, как прогнозируют результаты в NetPeak:
По словам докладчика, лучший способ избежать проблем — создать систему, которая не даст специалисту возможности ошибаться. Поэтому в NetPeak система всегда высылает специалисту на почту подсказки. Формируются следующие дайджесты:
Что специалист может не учитывать при подсчете эффективности, и как избежать подобных просчетов? В большинстве случаев, отметил эксперт, не учитывается от 10 до 40% продаж, которые генерирует рекламная кампания. В основном это:
Подсчитать оффлайн-конверсии можно при помощи:
В конце выступления Валерий отметил, что большая часть агентств сосредоточены на использовании инструментов, а не на решении проблем бизнеса своих клиентов. По словам Валерия Красько, интернет-маркетинг — это нечто большее, чем просто механическая работа с источниками, это решение проблем клиентов.
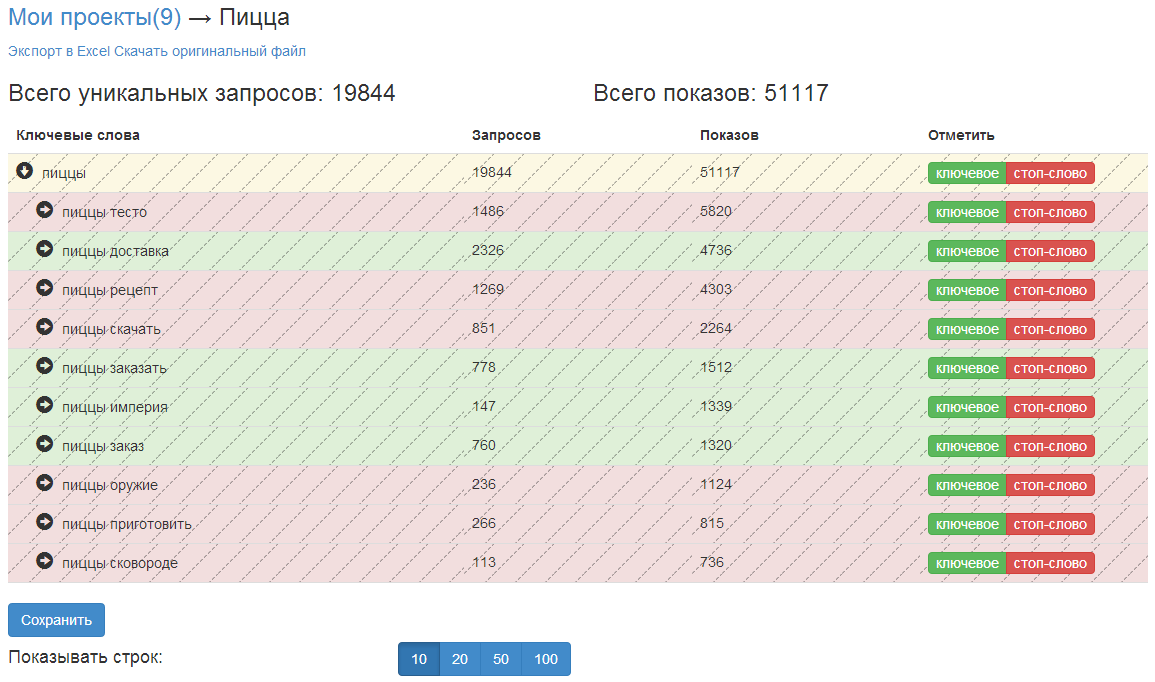
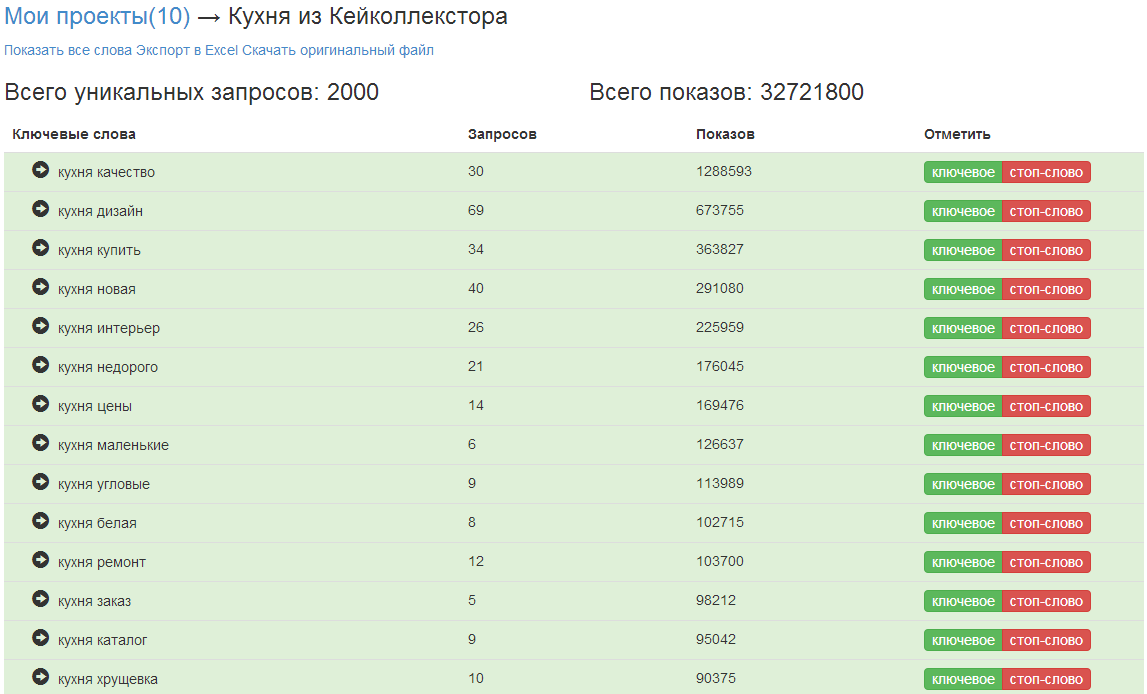
Получение из списка запросов список фраз для контекстных рекламных объявлений — задача, которую решает каждый рекламодатель. Поисковые системы по-прежнему не раскрывают информацию о запросах и выдают лишь данные о показах по ключевым словам, поэтому рекламодатель не знает, по каким запросам показывались его объявления. То есть если объявление показывалось, но на него никто не кликал, то про этот запрос рекламодатель ничего не узнает.
Андрей Иванов порекомендовал следующие сервисы для получения запросов:
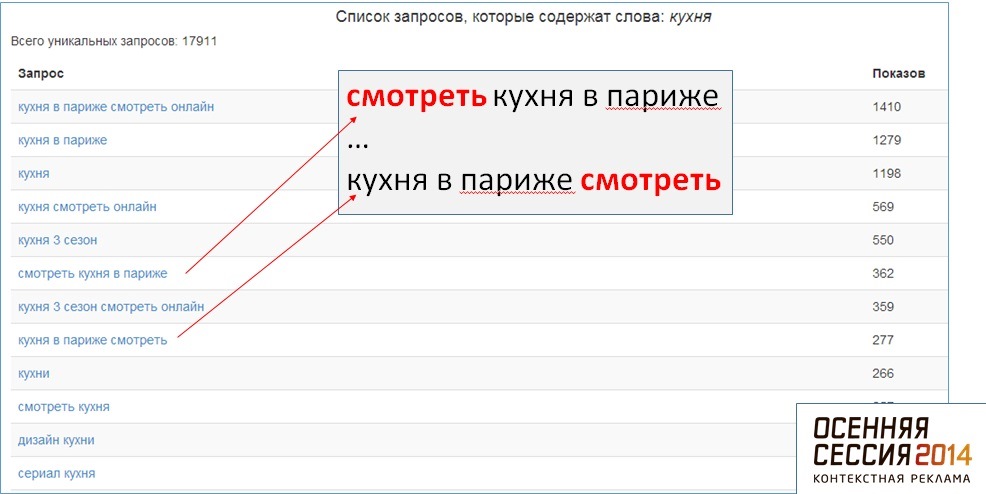
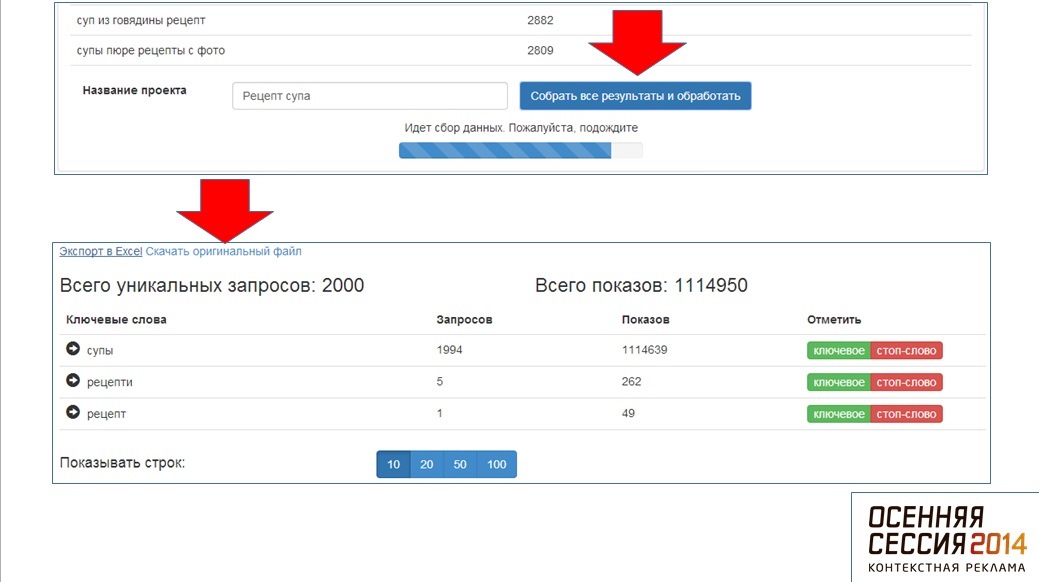
Полученные запросы выглядят следующим образом:
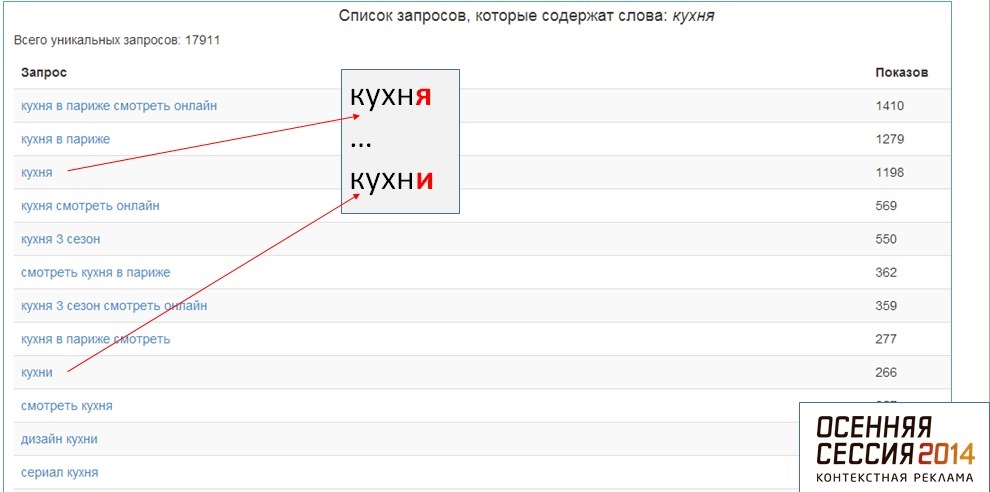
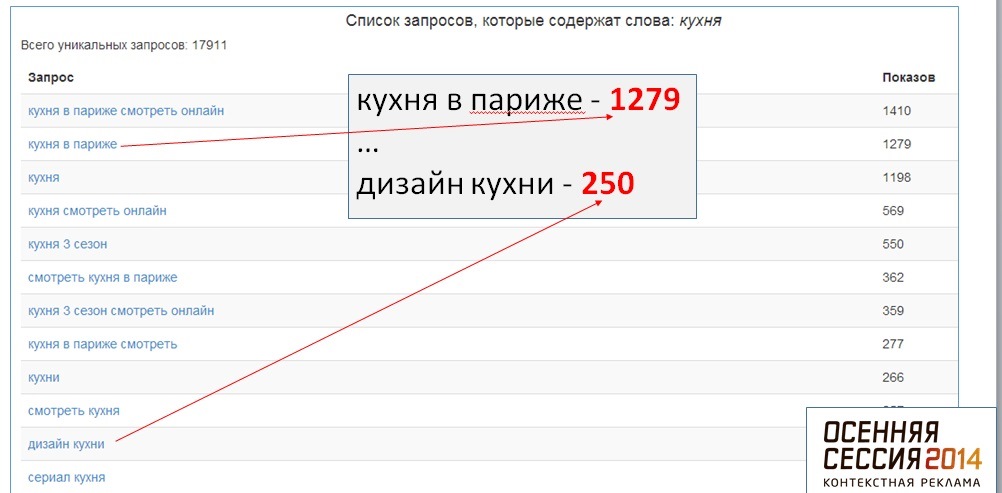
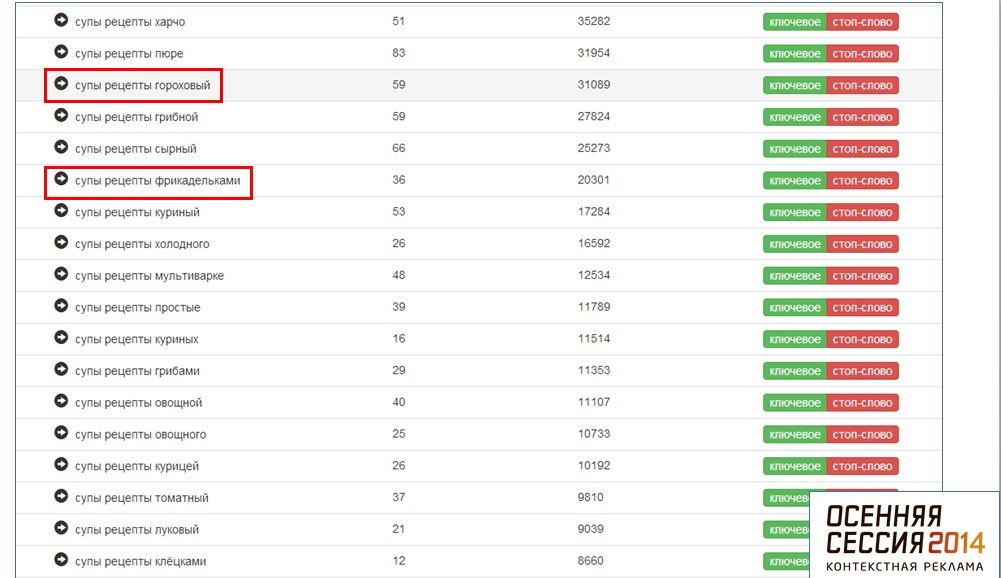
В длинном списке встречается множество нецелевых запросов, запросов с переставленными словами и т.д. Вот несколько алгоритмов подготовки списка:
Перестановка:
Словоформа:
Частоты:
По какому же алгоритму подбирать слова, какие сервисы использовать? По словам докладчика возможны три способа подбора:
Первый вариант работы выглядит следующим образом:
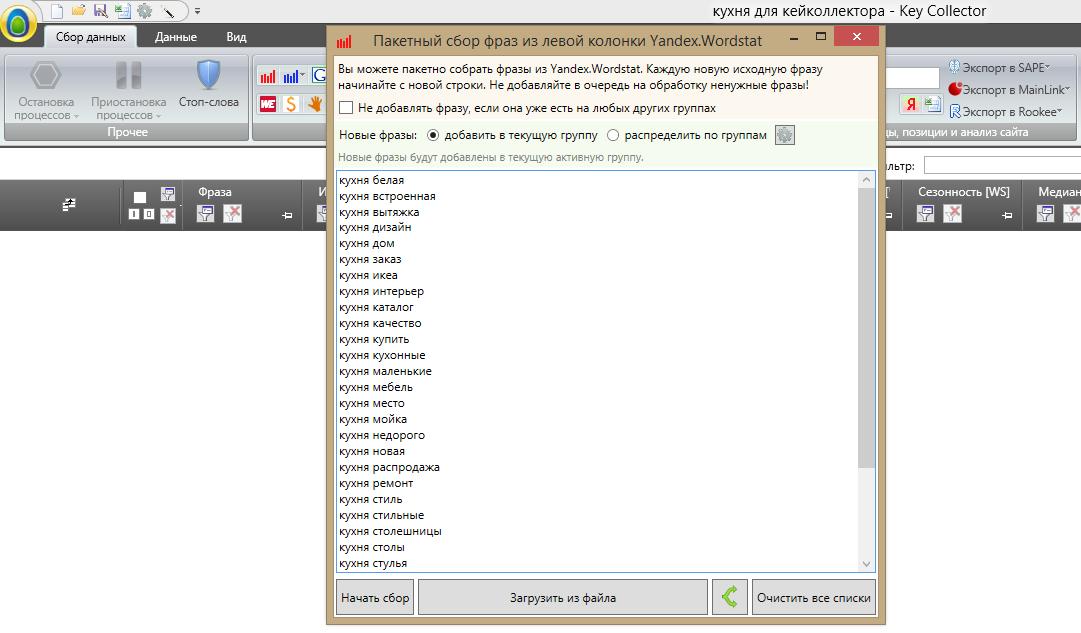
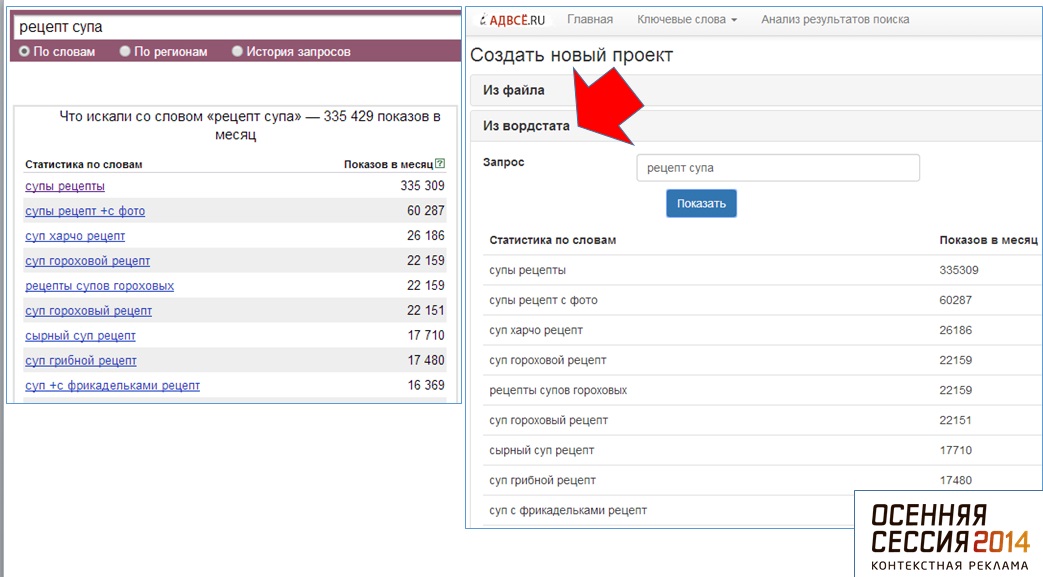
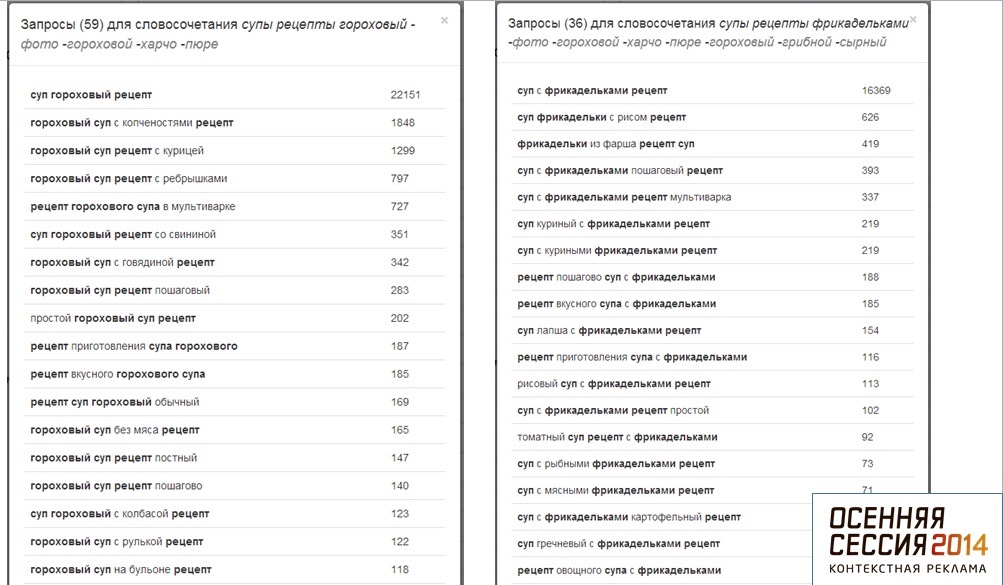
Второй вариант — совместное использование Advse и Keycollector. Это позволяет быстро извлечь максимум данных из Яндекс Wordstat. Важный момент — так как Wordstat не отдает по запросу больше 2 000 строк, то извлекать лучше данные по самому высокочастотному ключевому слову. После их нужно обработать в Advse — выбираем ключевые словосочетания из двух слов, чтобы они не дублировали друг друга. Вводим этот список в KeyCollector и быстро получаем максимум необходимых данных.
Наконец вариант с использованием «интеллектуальных надстроек» для работы с Яндекс.Wordstat, что позволит быстро выкачать данные. Один из таких сервисов, созданный Advse, Андрей Иванов порекомендовал собравшимся. С его помощью можно быстро получить точные ключевые словосочетания с максимальным охватом.
У нас вы также можете прочесть вторую и третью части обзора докладов.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}