2 октября в Москве прошла 4-я технологическая конференция Яндекса – . В мероприятии приняли участие сотрудники Яндекса и других компаний международного уровня – всего более 50 докладчиков. Выступления прошли в семи традиционных для конференции секциях:
 Михаил Агеев, Яндекс, рассказал об анализе неявных предпочтений пользователей и его использовании для улучшения формирования сниппетов документов в результатах поиска.
Михаил Агеев, Яндекс, рассказал об анализе неявных предпочтений пользователей и его использовании для улучшения формирования сниппетов документов в результатах поиска.
Хороший сниппет должен отвечать нескольким критериям:
Есть несколько известных алгоритмов выделения сниппетов – сопоставление текста документа с запросом, учет местоположения текста, структуры документа. Однако для высокорелевантных документов может возникнуть проблема большого числа соответствий запросу – из-за чего выделить релевантный фрагмент затруднительно. В таких случаях текстовых факторов недостаточно, и нужно привлекать дополнительную информацию о документе.
Обычно, когда пользователь ищет информацию в документе, его внимание распределено неравномерно – в основном он смотрит на те фрагменты документа, где содержится интересные ему данные. Для получения такой информации можно использовать технологию eye-tracking. Пример: пользователь ищет ответ на вопрос, сколько битых пикселей должно быть на экране iPad 3, чтобы его поменяли по гарантии, и его взгляд задерживается именно на том результате поисковой выдачи, который содержит ответ. Этот фрагмент и мог бы быть идеальным сниппетом.

Когда пользователь просматривает документ, он часто следует курсором мыши за своим взглядом. C вероятностью до 70% и точностью до 150 пикселей можно предсказать направление взгляда пользователя, используя данные о перемещении курсора, и таким образом, найти фрагмент, который заинтересовал его больше всего. Получит информацию о движении мыши достаточно просто – используя JavaScript browser API.
В связи с этим возникла идея для следующего исследования – собрать данные о поведении пользователей, добавить их к текстовым факторам и использовать полученную информацию для улучшения сниппетов.
Для проведения исследования требовалось выполнить задачи:
Информация о поведении пользователей собиралась по следующей технологии – была реализована игра, наподобие Яндекс Кубка по поиску, где пользователю требовалось ответить на 12 вопросов, используя поисковую систему. Пользователь должен предоставить ответ и URL, в котором этот ответ содержится. Игра проходила при помощи Amazon Mechanical Turk. За участие в игре пользователь получал $1, лучшие игроки также награждались бонусами. Чтобы отсечь роботов была реализована автоматическая проверка выполнения правил игры + капча.

Правила игры требовали, чтобы пользователи приходили через reverse proxy Яндекса. Было реализовано очень много reverse proxy, т.е. пользователь ищет, используя привычный интерфейс Google или Bing, но URL каждой страницы или ссылки на выданной странице заменяется на URL сайта Яндекса. В каждую страницу вставляется кусок javascript-кода для отслеживания поведения пользователя на данной странице. Таким образом, все действия пользователя записываются.
При трекинге движения мыши и скроллинга возникает следующая проблема – координаты движения курсора мыши представлены в javascript API в абсолютных координатах в окне браузера, а координаты текста зависят от разрешения экрана, версии и настроек браузера. Она была решена путем вычисления координат всех слов и на клиенте и добавления информации на сервер.
В итоге, получился набор данных о пользователе (известны все запросы, результаты, по которым он кликал, траектория движения мыши с привязкой к тексту), который использовался для генерации поведенческих факторов и предсказания интересных фрагментов. Кроме того, известен вопрос, на который пользователь искал ответ, результат, который он отправил в качестве ответа, и URL на котором он его нашел. На основе информации выводится множество, которое используется для обучения алгоритмов и проверяем качество их работы.
Статистика по собранным данным:

Как использовалась данная информация:
Как сформировать обучающее множество? Т.к. нет eye-tracking оборудования, нельзя точно предсказать, что смотрел пользователь. Но можно наверняка утверждать, что пользователь прочитал тот фрагмент документа, который он отправил. Поэтому обучающее множество формируется на основе тех страниц, URL которых пользователь отправил, следующим образом: положительными примерами считаются те фрагменты, которые пересекаются с ответом пользователя, а отрицательными все остальные. Это обучающее множество неполное и неточное, т.к. ничего неизвестно об остальных фрагментах, которые пользователь посмотрел. Но, тем не менее, этого достаточно для получения внятных результатов.
Сначала модель проверили на адекватность: ее обучили на одном множестве страниц, для которых были данные, и применили для предсказания интересности на другом множестве.
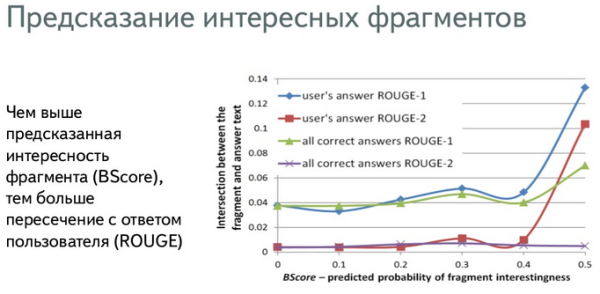
Если модель уверена, что фрагмент интересен пользователю, пересечение с ответом пользователя выше.
Итак, мы умеем предсказывать фрагменты на основе поведения пользователей. На основе этого фактора можно улучшить поисковые адаптации.
В качестве baseline-алгоритма был реализован подход генерации сниппетов, опубликованный в 2008 году Тапасом Канунго (Tapas Kanungo) и Доналдом Метцлером (Donald Metzler).
Для каждого предложения мы вычисляем 22 фактора:
Эти факторы объединяются в один на основе метода машинного обучения GBRT. И сниппет формируется при помощи baseline-алгоритма - набора фрагментов с наибольшим весом, так чтобы сниппет имел наибольший вес по комбинации этих факторов.
Далее мы объединяем текстовую релевантность фрагмента с предсказанной интересностью фрагмента по поведению пользователя при помощи линейной комбинации.

λ - вес поведенческого фактора
оптимальное значение λ подобрано путем экспериментов от 0 до 1.
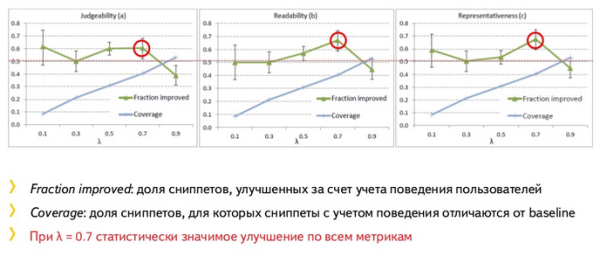
Как сравнить качество двух алгоритмов. Асессорам показывается два сниппета в случайном порядке, и они оценивают их по трем критериям: какой лучше отражает соответствие документа запросу, какой лучше читается, какой помогает найти релевантный ответ и решить, кликать ли на ссылку. Для каждого из факторов вычисляется доля сниппетов, для которых сниппет с учетом поведения оказался лучше, чем baseline.
На графиках представлены оценки асессоров для трех критериев. Мы видим, что при значении λ 0,7, можно получить оптимальное значение и улучшение качества сниппетов относительно baseline.
Какие еще задачи можно решать, предсказывая интерес фрагментов для пользователя? Есть такая задача, как вопросно-ответный поиск, когда пользователям нужно найти не просто документ, содержащий определенную информацию, а точный ответ на вопрос. Основной подход, построенный на поиске информации в текстах появляется следующий подход:
Невозможно применить шаблоны сразу ко всем предложениям и документам – слишком долго. Поэтому это разбивается на этапы.
Логично применить алгоритм предсказания интересных фрагментов для пользователей к третьему этапу – улучшению ранжирования пассажей, выделенных из текстового документа.
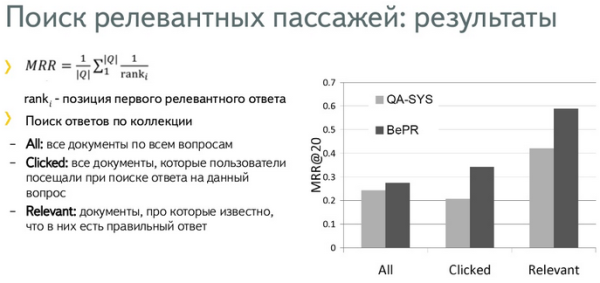
В качестве baseline-алгоритма взята система QANUS. Взяли фактор качества фрагмента с точки зрения системы QANUS и добавили поведенческий фактор:
Было проведено три эксперимента:
И получили, что качество ранжирования пассажей улучшилось во всех трех случаях, благодаря поведенческому фактору.
В заключение Михаил назвал основные ограничения данного подхода:
 Юрий Устиновский, Яндекс, рассказал об анализе поведения пользователей и персонализации поисковой выдачи.
Юрий Устиновский, Яндекс, рассказал об анализе поведения пользователей и персонализации поисковой выдачи.
Яндекс почти год назад анонсировал персонализацию поиска – алгоритм Калининград. Персонализация поиска позволяет двум разным людям на один и тот же запрос получить разную выдачу. Основная цель персонализации – сократить время решения пользователем поисковой задачи. Персонализация может использовать самые разные типы данных – в основном это кто задал запрос, документы ранжируются с учетом персонального контекста.
Персонализация делится на два типа:
Для извлечения персонального контекста короткая персонализация использует поисковые сессии – пользователь задает запросы в определенном порядке, перезадает запросы, и поисковая система учится понимать, какую выдачу ему нужно предоставить, и тем самым дает более качественные результаты. Поисковые сессии помогают в персонализации 60% запросов, т.е. для них можно использовать поисковый контекст с целью повысить качество.
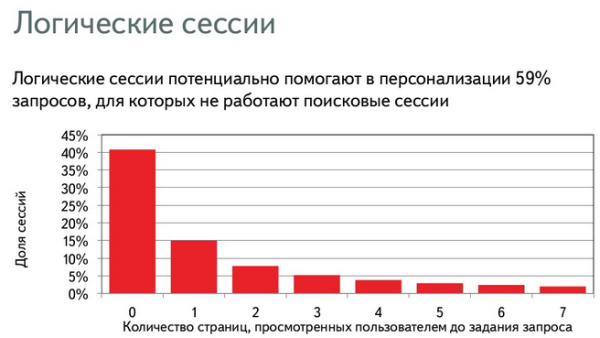
Однако для остальных 40% ничего нельзя сделать. Тогда приходится искать альтернативное решение, и в данной ситуации – это навигационные сессии, действия в Яндексе помимо переходов с выдачи (переходы по ссылкам, переключения между вкладками, открытие страниц из закладок). Навигационные сессии, объединенные одной информационной потребностью, называется логической сессией.
Выделение логической сессии из навигационной довольно сложная задача, но в текущем исследовании был использован простой, эвристический алгоритм: относим две соседние страницы к одной логической сессии, если между их посещением прошло менее T минут. Анализ показал, что в 59% случаев, когда у нас нет поисковых сессий, можно получить логические сессии. Значит, потенциально, можно использовать этот контекст, чтобы улучшить ранжирование.
На практике было проверено, действительно ли из этих данных можно извлечь полезный сигнал.
Для этого необходимо решить следующие задачи:
Обе задачи решаются одновременно с помощью машинного обучения. Тут возникает самая главная проблема в обучении персонализированной выдачи – это сбор персонализированных оценок, потому что невозможно подойти к каждому пользователю и спросить, какой документ ему понравился, а какой нет. Асессоры также не помогут – они не видят пользователя и не знают, что его привело.
Одно из возможных решений данной проблемы – посмотреть, на какие страницы пользователь кликал раньше, а на какие нет. Данный подход имеет как плюсы (возможность неограниченно наращивать обучающее множество), так и минусы (необходимость очистки данных от бесполезных сессий и шума).
Необходимая часть машинного обучения – это признаки, которые характеризуют связь документа с сессией, саму сессию, запрос, пользователя. В данном случае для каждого документа URL(i) было извлечено от 42 до 267 признаков.
Признаки:
1. Характеристики запроса (сколько документов найдено, насколько разнообразна выдача, навигационный ли запрос),
2. Характеристики логической сессии (время, проведенное на странице Doc(j), вероятность сформулировать запрос после Doc(j), количество страниц в логической сессии),
3. Близость между документом из контекста Doc(j) и выдачи URL(i) (вероятность того, что они окажутся в одной логической сессии, совпадают ли они, их хосты)
4. Близость между Doc(j) и URL(i), агрегированная по всем документам Doc(j).
5. Позиция URL(i) в неперсонализированной выдаче.
Затем обучаем Матрикснет на признаках, минимизируя квадратичное отклонение от разметки на обучающем множестве, и ранжируем согласно полученной оценке.
Для проверки того факта, улучшилось ли ранжирование, мы используем показатель MRR (mean reciprocal rank). Смотрим, как изменилось бы его значение, если бы раньше выдача была персонализированной. Чем он выше, тем лучше.
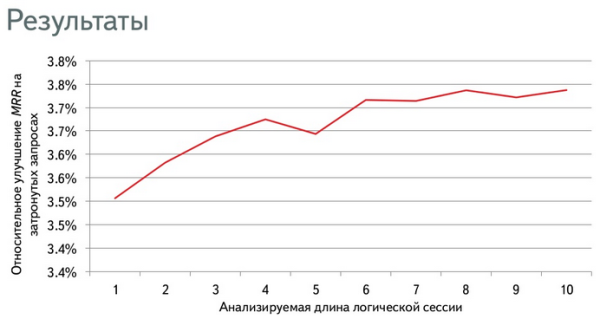
Для этого был проведен оффлайн-эксперимент с использованием старых логов (чтобы не предложить пользователям плохую выдачу, если эксперимент окажется неудачным). Результаты: чем больше мы берем документов из логической сессии, тем больше мы увеличиваем MRR.
Выводы:

 Теги:
Теги: