
Данная статья рассматривает быстрый, несложный и эффективный способ группировки по географическому признаку большого количества имеющихся в базе данных поисковой системы веб-ресурсов. Согласно данному способу во внимание принимается данные IP-адресов, доменные имена, индекс и код города. Новизна подхода состоит в возможности определения местонахождения по IP-данным (location-by-IP data) и анализа доменного имени. Этот метод предполагает использование инфраструктуры поисковой системы, что позволяет соотносить множество данных, имеющихся в базе с географическим показателем. Эксперимент был проведен над индексом поисковой системы Яндекс, результаты подтвердили эффективность данного метода.
Общие термины
Алгоритмы, дизайн, эксперимент, верификация.
Ключевые слова
Geotagging, географический поиск (GIR)
Введение
Поисковая система Яндекс индексирует все русскоязычные информационные источники, в том числе расположенные на доменах постсоветских стран. Сейчас в базе Яндекс находится более 600 млн. страниц больше, чем с 25 млн. сайтов, из которых почти 95% принадлежит России. Активная интернет-деятельность наблюдается пока только в крупных городах (Москва, Санкт-Петербург), но его стабильное популяризация ведется по всей России и странам СНГ, главным образом в отдаленных регионах. Данный факт значительно увеличивает важность и необходимость географического поиска для поисковой системы.
Вопрос частично находит свое решение в ручном редактировании каталога (http://yaca.yandex.ru). В настоящее время в каталог входит около 87 000 элементов, с прописанными вручную географическими данными; приблизительно у 48 000 элементов присутствуют идентифицирующие реквизиты российских городов. Географический реквизит составляют несколько семантических категорий места нахождения:
• место нахождения провайдера (физический адрес владельца источника);
• место нахождения контента (по географическим составляющим контента);
• территория обслуживания (на какой территории распространены сервисы веб-источника).
Прописанные вручную показатели могут передаваться субдоменам и индивидуальным страницам сайта, это не распространяется только на специфические домены (бесплатные хостинги и публичные домены). Около 140 000 российских сайтов получили географическую маркировку благодаря такой возможности (extended manual classification, EMC). Однако для комплексного исследования автоматических методов географической маркировки проиндексированных сайтов одной базы данных Яндекса недостаточно. EMC используется как верификационный набор для методов, рассматриваемых далее.
Согласно исследуемой области был определен прагматичный подход: методы должны быть эффективными, целесообразными, применимыми для максимального объема доступных данных.
1. Данные и Методы
В литературе можно найти много различных методов по использованию IP-данных о месте нахождения, доменных именах, контенте сайта (ссылки на информацию о расположении, например названия городов, телефонные коды городов, почтовые индексы) в геотаггинге (geotagging). Суть настоящего подхода заключается в наиболее эффективном сочетании множества источников географической информации.
Для регистрации городов было разработано два метода, основывающихся на:
• контенте сайта
• данных сайта (доменное имя, IP- адрес).
Рабочий процесс будет предполагать сочетание этих методов, как показано на Рис.1. Рассчитанные EMC точные (P) и выборочные (R) значения деклассифицированных сайтов, будут представлены для каждого этапа классификации. Пунктирные линии указывают на то, что результаты классификации объединены с исходными данными для последующего процесса, т.о. результаты классификации складываются в процессе работы.
1. Классификатор контент-анализа (CBC). Данный метод предполагает использование не оригинальных документов, а лишь их представления в поисковом индексе. Это не позволяет получить точный адрес страницы, зато увеличивает эффективность работы алгоритма. Были скомпилированы списки почтовых индексов 12 000 географических пунктов России [3] и телефонных кодов 2 000 городов [1] с названиями городов. Разработано два образца запросов. Первый предполагает поиск веб-страницы по почтовому индексу и по названию. Второй - по коду города, названию, элементам адреса (улица, номер телефона). Если с сайта получены некоторые из этих данных, значит, большинство из них относятся к одному и тому же географическому пункту.
2. Классификатор доменных имен (DLC). Данный метод предполагает анализ доменных имен. Во-первых, доменное имя, отражающее транслитерированное название города служит индикатором принадлежности сайта данному городу. Анализ исходных данных позволяет определить «хорошие» варианты транслитерации, например, сайты города Тверь: tver.eparhia.ru, tver.marketcenter.ru, http://www.tver.ru/ www.tver.ru. Во-вторых, это специфичные доменные имена, обычно являются аббревиатурами или уменьшительными названиями городов, например, nsk – Новосибирск, dolgopa – Долгопрудный. Если большинство известных сайтов имеют в доменном имени одинаковое название города, такой домен можно назвать «хорошим».
3. Классификатор иерархии доменного имени (DNHC). Суть метода в определении «хороших» городских доменов, сабдомены, которых могут относиться к тому же городу, например, spb.ru и omskcity.com (Санкт Петербург, Омск). Следует отметить, что DNHC используется дважды (Рис.1).
4. IP-данные о месте нахождения (Loc-by-IP). Предполагается использование внутренней базы данных IPREG, объединяющей IP-адреса хостов с соответствующими географическими пунктами. IPREG скомпилирована из различных регистрационных записей в Интернете. В IPREG собраны только «хорошие» блоки IP адресов.
5. Классификатор IP блоков (IP-blocks). Часто городским сайтам предоставляют хостинг местные провайдеры, которые не всегда состоят в IPREG или подобных базах данных. Поэтому, сайты, принадлежащие одному городу, образуют в адресном пространстве обширные блоки (блоки IP-адресов). Данный метод основан на определение «хороших» обширных блоков, тех в которых большинство известных сайтов принадлежат одному городу.
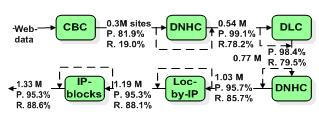
По данной схеме рабочего процесса можно сопоставить около 1,3 млн. российских сайтов из 2 млн. представленных в базе данных Яндекса.
2. Вычисление
О работе алгоритма с «хорошими» и качественными сайтами можно судить по данным EMC. Для проверки работы алгоритма в напряженных условиях был составлен набор тестовых программ. Методом случайной выборки был составлен список из 1200 сайтов, не больше чем по одному на домен второго уровня. Все сайты данного списка были автоматически промаркированы по городам или отнесены к «нулевому региону» (если город не был определен алгоритмом). Список был передан редакторам каталога Яндекса для ручного тегирования.
Полученные после этого данные позволят разделить набор тестовых программ на три категории:
• локальные сайты;
• «хорошие» сайты, не «замусоренные» (без дорвеев, полностью доработанные, актуальные);
• полное множество сайтов.
Результаты анализа алгоритма для всех этих категорий представлены в Таблице1. В первой колонке находится подмножество локальных сайтов (1). Во второй и третьей колонках автоматически определенный нулевой тег был интерпретирован как «без гео категории». Спорным остается вопрос о критерии дифференциации локальных, глобальных и ненужных сайтов; «нулевой регион» также говорит о том, что использованный метод по определению города оказался неуспешным. В итоге точные (Р) и выборочные(R) значения в данном случае остались практически без изменений.
Таблица 1. Результаты вычислений
| Локальные сайты | Локальные + нелокальные сайты | Вся выборка (+ ‘мусор’) | |
| число сайтов | 723 | 1048 | 1200 |
| точные | 0,917 | 0,722 | 0,688 |
| выборочные | 0,751 | 0,696 | 0,667 |
| F1 | 0,826 | 0,709 | 0,677 |
Заключение
В этой статье мы рассмотрели возможные пути решения вопроса о геотаггировании сайтов. Методы предполагают использование большого количества источников информации, таких как IP-данные о месте нахождения, доменные имена, а также информация по контенту: прямой поиск почтового индекса и кода региона на страницах сайта. Методы функционируют в рамках инфраструктуры поисковой системы, стабильно и качественно соотносят данные поисковика с географическими данными.
Новый подход был разработан для предоставления возможности определить географическое положение сайта по контент-данным в совокупности с IP-адресом. Эта методика геотагирования представляется более точной, по сравнению с традиционными методами, основанными на анализе регистрационных данных в Интернете. Следует отметить заслугу данной методики за значительный вклад в полный анализ доменных имен.
Проделанные вычисления подтверждают приемлемость подхода в интернет-индустрии. Однако, согласно тем же вычислениям, основной трудностью подхода остается определение критериев отличия локальных сайтов от глобальных или национальных. Этот вопрос будет решен в ближайшей перспективе: планируется разработать классификатор сайтов, который будет работать без учета географического контекста.
Авторами доклада выступили специалисты компании Яндекс:
Михаил Маслов – руководитель отдела разработки поисковых сервисов
Алексей Пяллинг – разработчик
Павел Браславский – менеджер проектов отдела веб-поиска .

 Теги:
Теги:

