16 мая в Москве прошла конференция Яндекса Yet Another Conference on Marketing, посвященная обсуждению опыту и проектов, связанных с Machine Learning, большими данными, вычислениями в маркетинге и рекламе.
 Послеобеденную секцию открыл Игорь Ларин, IBM, который рассказал о том, как будет трансформироваться профессия маркетолога в ближайшие 5 лет, какие новые вызовы встанут, и как с помощью новых технологий можно эффективно решать задачи. Для этого был проведен опрос почти 2000 директоров по маркетингу по всему миру (60 из них из России и стран СНГ).
Послеобеденную секцию открыл Игорь Ларин, IBM, который рассказал о том, как будет трансформироваться профессия маркетолога в ближайшие 5 лет, какие новые вызовы встанут, и как с помощью новых технологий можно эффективно решать задачи. Для этого был проведен опрос почти 2000 директоров по маркетингу по всему миру (60 из них из России и стран СНГ).
Как показали результаты исследования, в ближайшие 5 лет профессия директора по маркетингу станет сложнее – так считает 79% респондентов. Это связано с цифровой революцией, большим количество данных, менее лояльными и более требовательными заказчиками, которые к тому же становятся гораздо информированнее.
Однако к этим усложнениям полностью готовы лишь 48% опрошенных.
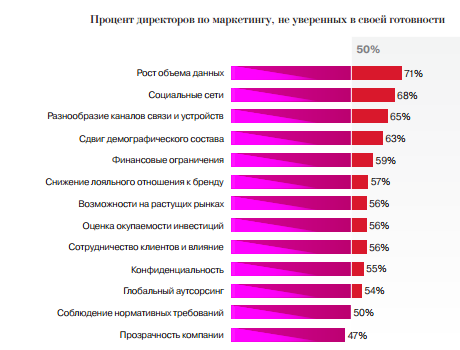
При сравнении факторов, которые будут больше всего влиять на маркетинговую деятельность, и факторов, к которым меньше всего готовы, выявилось три проблемы:
1) Взрывной рост объема данных – многие просто не знают, что с ними делать.
2) Социальные сети – не умеют работать с ними.
3) Разнообразие каналов связи и устройств.
Чтобы приспособиться к трудностям и трансформировать сложности в новые возможности 73% опрошенных ответили, что готовы инвестировать в технологии управления информацией, 69% — в сбор и хранение данных, 65% - в анализ информации.
Кроме того, по словам респондентов, компании готовы повышать применение цифровых технологий:
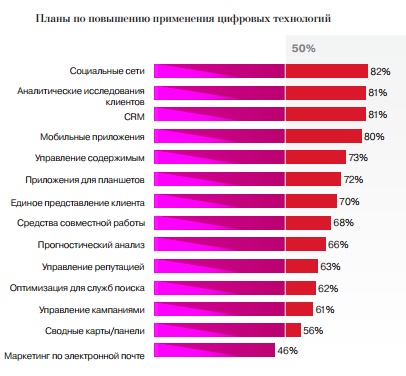
Внедрению новых информационных технологий мешает, прежде всего, их высокая стоимость и отсутствие уверенности в окупаемости. Около половины респондентов также назвали проблемы с внедрением инструментов и недостаток навыков у потенциальных пользователей.
Что касается измерений эффективности маркетинга, на первом месте стоит ROI.
 Секцию продолжил Михаил Левин, Яндекс, который рассказал о прогнозировании кликов в контекстной рекламе.
Секцию продолжил Михаил Левин, Яндекс, который рассказал о прогнозировании кликов в контекстной рекламе. Задача Яндекса – это не только показать объявление, по которому кликнут пользователи, но и выбрать именно то, которое принесет наиболее высокий доход. В каждом из блоков идет аукцион – CPM (вероятность клика умножить на ставку) - Яндекс оценивает вероятность клика, сколько за него получит денег.
Очень важно правильно прогнозировать цену клика. Это можно сделать несколькими способами:
- Хранить статистику показов объявления – но это примитивный подход, вероятность будет сильно зависеть от запроса,
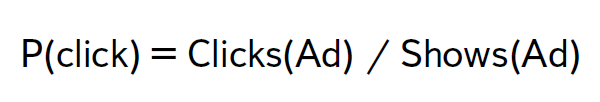
- Можно добавить к этому учет поискового запроса.

Но реализовать такой подход невозможно, т.к. получается слишком много данных.
- Хорошая альтернатива поисковому запросу – ключевая фраза. Данных получается также немало, но ими можно управлять.
![]()
Но данную модель также можно улучшить. Например, у нас есть объявление о продаже iPhone, ключевая фраза iPhone и запросы “iphone 5”, “iphone 4” и “iphone инструкция”. Одно слово или даже цифра может сильно повлиять на вероятность запроса, и тут приходится использовать «хвост» запроса. Их много, но нужно выбирать самые важные.
При прогнозировании клика нередко возникают проблемы - например, объявление новое и по нему нет статистики. В данном случае следует посмотреть на статистику всего домена. Если же и сам домен новый, то необходимо использовать релевантностные факторы.
Как смешивать статистику? Примеры формул:

Кроме статистических факторов можно учитывать регион, номер страницы, время дня, день недели, релевантность текста объявления... и копить статистику, а потом делать срезы. Но это нецелесообразно: количество срезов будет расти, но какой бы срез не взять, по нему будет мало кликов, что не позволит сделать выводы.
От обычных статистических подсчетов переходим к машинному обучению. Но как определить, стало ли лучше? Можно использовать метрики:
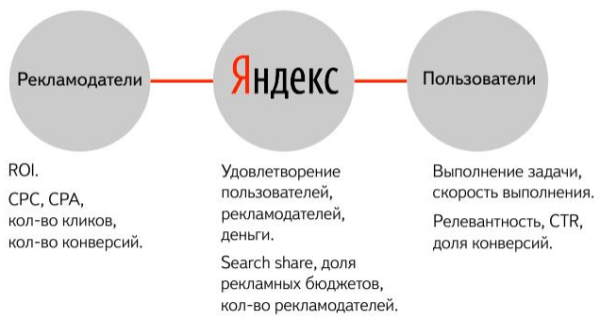
Но даже если метрики показывают, что стало лучше, на самом деле это может быть не совсем так: если мы ориентируемся на исторические данные – это может быть совпадение, до и после запуска формулы может измениться поведение пользователей и рекламодателей. Кроме того, некоторые метрики меняются очень медленно, а полгода – слишком большой срок для внесения изменений.
В итоге получается новая сложная функция качества, постепенно меняющаяся:

Новый алгоритм запускается на 2% пользователей, проверяется отличается ли эксперимент от контроля, а дальше принимается решение.
 Станислав Видяев, Google, рассказал об инструменте Universal Analytics.
Станислав Видяев, Google, рассказал об инструменте Universal Analytics.
Основная идея нового инструмента – это переход от сессий к пользователям
Вечная проблема веб-аналитики – это отслеживание по кукам. Куки принадлежат к конкретному устройству и их сложно передавать между ними - до сегодняшнего дня не существовало большой индустриальной платформы (к тому же бесплатной), которая бы позволяла это делать. Проблема усугубляется тем, что между браузерами куки тоже не передаются, и в итоге у нас получается огромное количество уникальных посетителей. И наконец, есть еще одна проблема – невозможность отследить действия пользователей в офлайне.
Что делает в этом отношении Google Analytics. В рамках стандартной версии есть серия отчетов – многоканальные последовательности. И тут можно посмотреть, с каких источников приходил пользователь, и где конвертировался. Но вся эта последовательность выстраивается в рамках 1 куки. Тут мы опять сталкиваемся с ограничением – у нас есть возможность провести атрибуцию только в рамках 1 устройства и 1 браузера.
Инструмент Universal Analytics будет работать на другой куке. Так выглядит стандартная кука:

Universal Analytics использует новые куки + User ID. Преимущества: все реферальные данные хранятся на сервере Google, что позволяет быстрее их обрабатывать.
![]()
Разница между старым и новым подходом. Например, пользователь зашел на сайт со смартфона, потом 2 раза с ноутбука(зарегистрировался и совершил покупку), и еще раз со смартфона. В рамках стандартной куки – это три разных пользователя.
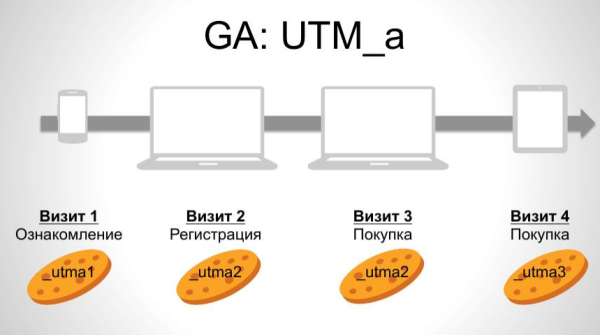
В рамках Universal Analytics - это 2 разных пользователя. Если пользователь идентифицирует себя, куки переписываются, и мы получаем всю историю взаимодействий пользователя. Если пользователь себя не идентифицирует, это посещение выпадает из Universal Analytics.
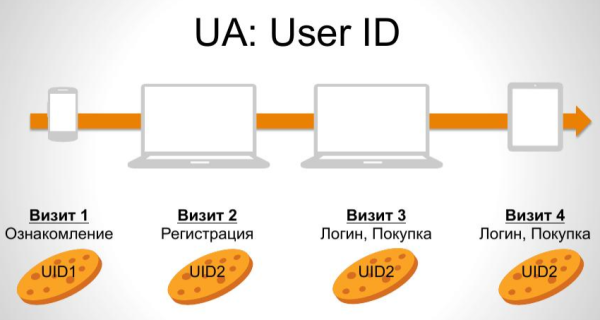
Как Universal Analytics позволит связать онлайн и офлайн: все User ID через API можно будет забрать себе в CRM, где их можно будет связать с Client ID. Когда произойдет офлайн действие, через особый Measurement-протокол можно будет отдавать эти действия в качестве метрик Google Analytics в формате CSV в Universal Analytics.

 Теги:
Теги: