
Современные поисковые машины оставляют SEO-специалистам немного документированных возможностей для исследования их алгоритмов. Более того, большинство «дырок» и недокументированных возможностей, которые позволяли напрямую или косвенно анализировать поисковые системы, сейчас закрыты.
Что остаётся SEO-специалисту? Что остаётся людям постоянно находящимся в поиске истины и интригующих подробностей? Что утоляет информационный голод и любопытство?
Остаётся только взять в свои руки доступные аналитические инструменты и начать проводить новые исследования, сделать свой шаг «навстречу». Работать с поисковой системой как с классическим чёрным ящиком.
(def) Чёрный ящик — объект, детальная структура которого остаётся неизвестной, но о работе которого, можно судить по его реакции на внешнее воздействие.
Итак:
- Подаём сигнал на вход.
- Ожидаем реакции (индексации и апдейта тех факторов, на которые мы пытались воздействовать) [1].
- Делаем выводы и производим следующую итерацию.
- Круг замыкается.
Это классическая схема взаимодействия любого экспериментатора с изучаемым объектом, в роли которого (в нашем случае) выступает поисковая система.
Эксперимент или простое наблюдение?
Эксперимент отличается от простого наблюдения своим активным взаимодействием с изучаемым объектом. Обычно эксперимент проводится для подтверждения или опровержения какой-либо гипотезы.
Для ряда базовых задач в SEO достаточным оказывается пронаблюдать за успешными проектами и сделать соответствующие выводы. Это связано с тем, что формула ранжирования в поисковой системе Яндекс строится по принципу «подстройки» под ручные оценки.
Асессоры Яндекса оценивают тройки «запрос-регион-документ» и расставляют оценки согласно принятой в компании классификации. Далее множество ручных оценок подаётся на обучение алгоритму, и на выходе получается ранжирующая формула. Для геонезависимых запросов [2] тройка «запрос-регион-документ» преобразуется к паре «запрос-документ».
Далее, исходя именно из этих принципов, и будут строиться наши наблюдения и эксперименты.
Исследование 1: распределение входящих ссылок на сайт по числу слов в анкоре
Идея данного наблюдения чрезвычайно проста:
- Мы подбираем ряд сайтов, которые активно не продвигаются в поисковых системах. То есть имеют только естественные входящие ссылки.
- Анализируем эту массу естественных ссылок в разрезе числа слов в каждом анкоре и строим соответствующую гистограмму: распределению анкоров по количеству слов в них.
- Берем ряд заведомо «SEOшных» проектов и проделываем аналогичную процедуру для них.
- Производим сравнение.
В качестве экспериментальных «естественных сайтов» были взяты 6 сайтов в IT-тематике с хорошими позициями в Яндексе. Получены все входящие ссылки на каждый из проектов, и произведен анализ входящих ссылок по числу слов в анкорах.
Результаты построения представлены на Рис.1.
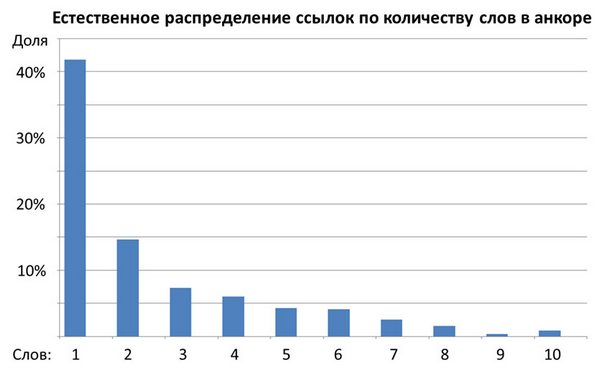
Рисунок 1. Распределение анкоров ссылок по числу слов для группы «естественных» сайтов. Успешные сайты в IT-тематике и не находящиеся на продвижении.
Как видно из гистограммы, преобладают ссылки с 1 словом в анкоре. Среди всех анкорных ссылок их доля составила порядка 40% от общей ссылочной массы. Анкоры с 2 словами составили уже всего порядка 15%. Ссылки с 3 словами в анкоре составили порядка 7,5% всей массы, ссылки с 4 словами в анкоре – около 5-6%. И так далее.
Давайте сравним это с SEO-проектами, с проектами, которые находятся на активной фазе продвижения. Сделать это чрезвычайно просто: достаточно выгрузить всю ссылочную массу из панели Вебмастера от Яндекса и построить в Excel советующую гистограмму.
Один из типичных SEO-проектов представлен на Рис.2.
Как видно из гистограммы для взятого нами SEO-проекта доля анкоров с 1 словом снизилась до 22,5%, с 2 словами – 15%, а далее происходит самое интересное. Число ссылок с 3 и 4 словами превышает число ссылок с 2 словами и превосходит 20% от общей ссылочной массы.
Это одно из типичных распределений для рядового SEO-проекта продвигающегося по двух-, трёх- и четырехсловным коммерческим запросам.
Рисунок 2. Распределение анкоров ссылок по числу слов для сайта продвигающегося с помощью ссылок. Проект продвигается по группе двух- и трёхсловных запросов.
Пример 2: типичный трафиковый проект представлен на Рис.3. Смотрите также комментарии к рисунку.
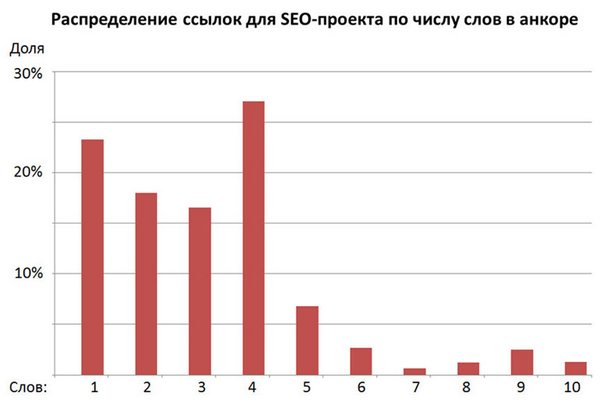
Рисунок 3. Распределение анкоров ссылок по числу слов для типичного сайта продвигающегося по трафику. Характерных «запил» в области четырехсловных запросов. Их доля – порядка 28-30% среди общей массы.
Другие примеры?
Автор призывает читателя произвести самостоятельное изучение ваших неуспешных проектов и построить соответствующие гистограммы. Имеются основания утверждать, что такой фактор используется поисковыми системами для оценки «естественности» входящей ссылочной массы на сайт.
Развитие: от наблюдения до эксперимента
Наиболее правильным продолжением предложенного выше наблюдения будет составление гистограммы для своих проблемных проектов и проведения полноценного эксперимента с чёрным ящиком – поисковой системой. Сделайте распределение входящей ссылочной массы на ваш сайт наиболее похожим на естественное распределение, получите результат!
(!) Важно: не делайте выводов по проектам с малым числом входящих ссылок. Данное статистическое распределение анкоров по числу слов имеет смысл только при относительно большом количестве входящих ссылок (более 300-500), и, соответственно, высококонкурентных запросов.
(!) Важно: описанное выше статистическое распределение ссылок является лишь одним из факторов. У поисковой системы в распоряжении имеется более 700 других сигналов, и, задействовав только какой-то один из них, не получится добиться выдающихся результатов. Требуется задействовать сразу множество факторов для достижения цели.
Исследование 2: использование Яндекс.Метрики для расчета факторов ранжирования
Спор относительно использования или не использования данных из Яндекс.Метрики для ранжирования сайтов не утихал никогда. Аргументами со стороны противников использования Метрики для расчета части поведенческих факторов являются:
- Отсутствие кода счётчика на всех сайтах (полнота).
- Отсутствие официальных заявлений и даже некоторые публичные отрицания использования этих данных для ранжирования [3].
Аргументы сторонников использования Метрики значительно более весомые:
- Уникальные данные по источникам трафика (не поискового) и их величина (доля в посещаемости сайта).
- Анализ заходов по ссылкам со сторонних сайтов.
- Возможность расчета BrowseRank’а внутри хоста [4] для выявления наиболее значимых страниц, приковывавших внимание аудитории сайта.
- Региональные распределения пользователей.
Действительно, данные, которые Яндекс может получить от Метрики, представляют чрезвычайно полезную информацию для поисковой системы.
Остаётся главный вопрос: достаточна ли полнота? Другими словами, достаточно ли сайтов используют Метрику, чтобы использовать эти данные, или они не будут отражать реальной картины?
Именно на исследование этого момента мы постараемся обратить наше внимание.
Данные по распространению Яндекс.Метрики на сайтах
В результате анализа выдачи по 100 высококонкурентным поисковым запросам была составлена следующая статистика распространения [5]:
- 9 из 10 сайтов в ТОП-10 по высококонкурентным запросам используют Метрику.
- Доля сайтов, использующих Метрику, вглубь выдачи падает (на 2, 3 и последующих станицах доля сайтов с Метрикой меньше).
Эти числа позволяют утверждать, что полнота для использования этих факторов будет достаточной, и учитывать эти данные важно и нужно.
Результаты других исследований [6] при мониторинге по 10 000 поисковым запросам подтверждают достаточную полноту сайтов с Метрикой (более 80% по ТОП-50).
(!) Важно: для получения наиболее точной статистики по распространению Метрики на коммерческих сайтах мы рекомендуем исключить из рассмотрения неорганические примеси. То есть сайты, «подмешанные» в выдачу по технологии СПЕКТР, и новостные результаты (быстроробот).
Что делать Яндексу с сайтами, не использующими Метрику?
Для сайтов, не использующих Яндекс.Метрику, многие аналогичные факторы могут быть рассчитаны из анализа поведения сёрфинга пользователей:
- с установленным Яндекс.Баром (Яндекс.Элементами);
- использующих соответствующий Браузер от этой поисковой системы.
Так или иначе, для учёта всех поведенческих метрик мы рекомендуем устанавливать на ваш сайт код счётчика (особенно если ваш сайт обладает хорошими поведенческими характеристиками)
Исследование 3.1: базовое использование языка запросов поисковой системы
У поисковой системы Яндекс имеется ряд документированных операторов расширенного поиска [7], которые могут использовать пользователи для настройки результатов выдачи. Эти операторы крайне полезны для осуществления сложного поиска и поиска малораспространенной в сети информации. Мы также можем использовать эти операторы для определения некоторых базовых свойств построения индекса в этой поисковой системе.
Обратим своё внимание на тег Title.
1) В поисковой системе имеется специальный оператор [title:], позволяющий ограничить область поиска только им. А также оператор, указывающий расстояние в словах от одного слова до другого [/].
2) Воспользуемся ими для поиска документов с длинным тегом Title. Для этого введем в поисковую систему запрос вида: [title:(москва /(+62 +62) москва)]. На первом месте будет документ с 548 словами в теге Title. Документ находится в индексе.
3) Взяв последние 3-4 слова, можно найти этот документ по точной фразе из тега Title с 548 словами (!).
4) Это свидетельствует о том, что распространенное заблуждение оптимизаторов относительно индексации только первых 70/150/250 символов в теге является ошибочным.
Исследование 3.2: контекстные ограничения в Title
Большой интерес представляет поиск с точно заданным в словах расстоянием. Как показывает практика, Яндекс ассоциирует между собой слова, которые находятся на расстоянии не более 62 слов.
Это видно из простых запросов, представленных на Рис. 4. Смотрите также подпись к рисунку. Вы можете изменить слова «мебель» и «купить» из запросов на любые другие.
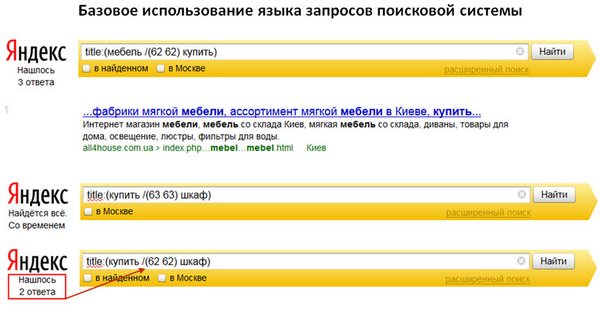
Рисунок 4. Демонстрация контекстных ограничений между словами в теге Title. Документы с заданным расстоянием в словах 62 и менее находятся. Документы с заданным расстоянием в 63 слова и более не находятся никогда.
Выводы
Представленные в данной статье экспериментальные материалы являются иллюстрацией лишь малой доли той информации, которую может получить SEO-оптимизатор, проявив любопытство.
Автор призывает пытливых и любознательных SEO-специалистов не останавливаться на полученных результатах, а проводить свои собственные небольшие исследования и глобальные эксперименты, направленные на изучения принципов ранжирования поисковых систем. Удачи!
Список литераторы для ознакомления
1. Анализатор АПдейтов от Трофименко, 2008,
2. Типы поисковых запросов, 2012,
3. Конференция «Поисковая оптимизация и продвижение сайтов в Интернете», 2012,
4. Введение в BrowseRank, 2011,
5. Сервис анализа ТОП-10 SEO hint, 2012,
6. Конференция СПИК, 2013,
7. Памятка по языку запросов от Яндекса,

 Теги:
Теги:










