
Зачем поисковики борются со ссылочным спамом? Затем, что любой спам снижает качество поисковой выдачи любой поисковой системы. Ссылочный спам направлен на борьбу с сайтами и страницами, чьи позиции были получены не естественным образом, с целью манипуляции алгоритмами поисковика.
PageRank
Едва ли не первым алгоритмом, направленным на борьбу со спамом, но не ссылочным, а с текстовым является алгоритм PageRank от Google.
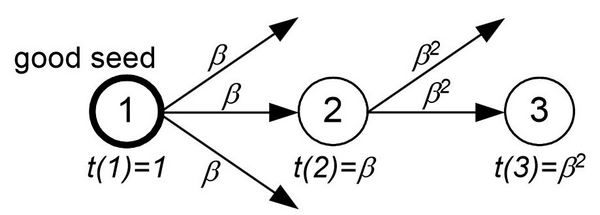
PR(A)=(1-d)+d(PR(T_1 )/C(T_1 ) +⋯+PR(T_n )/C(T_n ) ), где
PR(A) — вес страницы A;
PR(T_n) — вес страницы, ссылающейся на страницу A;
C(T_n) — число ссылок со страницы T_n;
d — коэффициент затухания, обычно принимается равным 0,85;
1-d — элемент телепортации.
Принцип работы PageRank можно описать следующим образом:
Представим, что у нас есть «Путешественник» перемещающийся по ссылкам в интеренете случайным образом. Он с равной вероятностью может либо перейти по следующей ссылке (одной из) на странице, либо телепортироваться в произвольное место. Вероятность перехода по ссылке и есть PageRank.
Опираясь на формулу не сложно понять, что нужно для манипуляции PageRank:
- страница T_n имеет высокий вес;
- страница T_n имеет мало исходящих ссылок;
- на страницу A ссылается большое количество страниц T_n;
- расстояние между страницами должно быть равно 1 (с каждой ступенью удаления, вес уменьшается в 0,85 раза).
Кроме того, можно сделать вывод относительно ссылок, размещаемых на вашей странице:
- ссылки не отнимают вес у страницы, на которой они находятся;
- при добавлении каждой дополнительной ссылки со страницы, смежные ссылки передают меньший вес.
По иронии судьбы PageRank, направленный на борьбу с текстовым спамом, положил начало эпохе ссылочного спама. Для борьбы с этим видом спама применяется множество алгоритмов, которые описываются в данной статье.
TrustRank
Задача алгоритма обнаружить страницы и сайты, которые вероятнее всего являются спамом, а также те, которые вероятнее всего являются достойными.
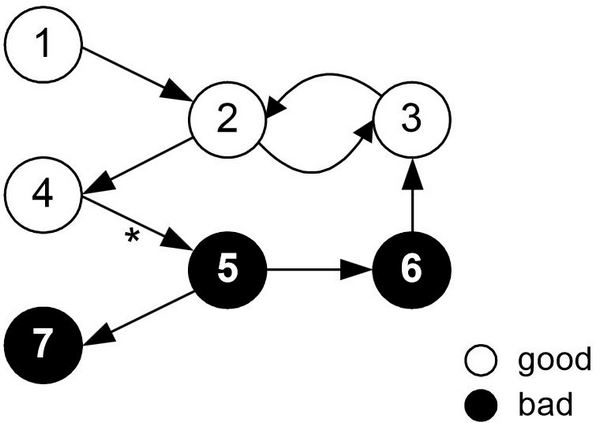
Алгоритм основан на полуавтоматическом обнаружении, хороших, не спамных страниц. Алгоритм полагается на утверждения:
- хорошие документы редко ссылаются на плохие;
- та тщательность, с которой владельцы хороших документов ставят ссылки на другие документы, обратно пропорциональна количеству этих ссылок.
Принцип работы следующий:
- На основе инвертированного PageRank, вычисленного не по количеству входящих, а наоборот — по количеству исходящих ссылок со страницы, выбираются те сайты, для которых этот показатель оказался наибольшим.
-
Для этих сайтов производится ручная оценка по принципу (в оригинальном алгоритме указано, что достаточно разметить буквально 200 сайтов с помощью экспертной оценки, для того, чтобы можно было оценить WEB в целом):
0 — спамный
1 — достойный
-
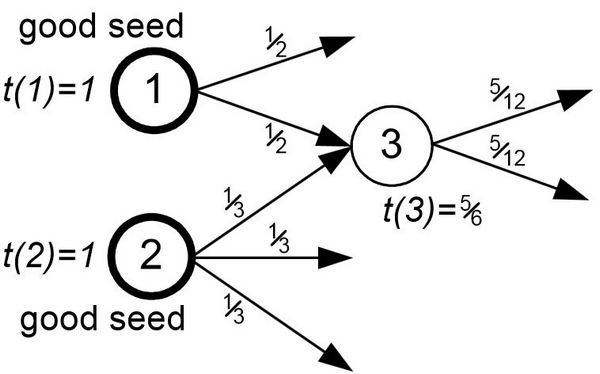
Далее производится распространение TrustRank по следующему принципу:
- чем дальше от источника — тем TrustRank меньше, причем степень уменьшения равна количеству шагов от источника;
- TrustRank разделяется поровну между всеми исходящими ссылками.
был разработан и внедрён в 2004 году.
Примечание: Описан алгоритм, использованный Yahoo. Другие поисковые системы могут использовать близкие алгоритмы. Подтверждением этого может служить использование , приобретённого Google в 2003 году.
Высоким TrustRunk обладают:
- сайты из каталогов Yaca и Dmoz;
- сайты имеющие большой возраст;
- сайты размещающие только уникальный контент;
- сайты, тщательно отбирающие ссылки для размещения в своём контенте.
Задумывались ли вы когда-нибудь, почему Википедия присутствует вверху выдачи по подавляющему большинству поисковых запросов, при этом новые статьи могут практически не иметь ни внутренних, ни внешних ссылок? Потому, что ей фактически вручную присвоен очень высокий уровень доверия.
Topic-sensitive PageRank
Помимо алгоритмов, описанных выше, поисковая система вычисляет вес, передаваемый по ссылкам, с учётом тематики страницы-донора.
Подробно прочитать про алгоритм можно в , поскольку примерный принцип работы, я думаю, очевиден.
Интересна только одна деталь: для каждой тематики создаётся вектор. Таким образом между разными тематиками можно рассчитать близость этих векторов. Другими словами, для получения тематической близости, не обязательно использовать идентичные тематики.
В таблице представлены данные — близость между векторами, рассчитанное в оригинальном исследовании. 0 — бесконечно удалены, 1 — совпадают.
(Картинка кликабельна)
Манипуляция на основе факторов, учитываемых алгоритмом может осуществляться:
- покупкой ссылок на тематически совпадающих донорах с высоким PR;
- на тематически близких донорах с высоким PR.
BrowseRank
Еще одним инструментом поисковых систем является BrowseRank.
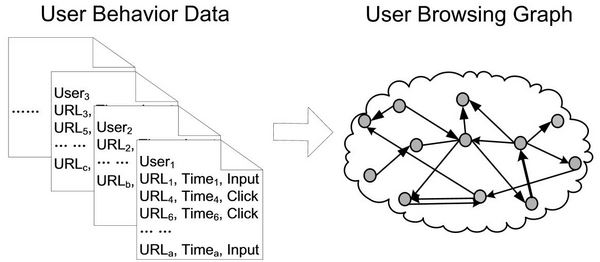
Отличие от PageRank состоит в структуре ссылочного графа. В технологии PageRank ребрами графа служат ссылки, а узлами — документы. В BrowseRank применён другой подход: ребрами являются переходы между документами, а узлами по-прежнему остаются сами документы.
BrowseRank можно назвать своего рода гибридом между поведенческими и ссылочными факторами.
В BrowseRank используется информация о продолжительности пребывания пользователя на странице, факт перехода на другой документ и способ этого перехода: прямой ввод а адресную строку, либо переход по ссылке.
Откуда поисковики могут брать эту информацию?
Предлагаю подумать:
- зачем поисковикам нужны собственные бары (Яндекс-Бар);
- зачем поисковики разрабатывают собственные браузеры, а также вкладывают миллионы долларов на их продвижение (Google Chrome).
статьи с алгоритмом расчета.
Накручивать BrowseRank не рекомендуется, поскольку поисковики обладают множеством естественных данных.
- во-первых, у поисковика есть граф кликов сайта донора и накрутка приведёт к его перекосу;
- во-вторых, накруточные сервисы часто «палятся», так например пользователи популярного Userator оставляют за собой «след» в виде источника перехода Userator.ru.
Другие факторы борьбы со ссылочным спамом
Нами были рассмотрены прямые метрики антиспама. Теперь перейдём к косвенным или, если хотите, к динамическим. Отличаются они тем, что фактически направлены на борьбу с механизмами заспамливания выше описанных алгоритмов.
Динамика прироста ссылок
В первую очередь учитывается динамика прироста ссылок.
Это уже давно всем известный ссылочный взрыв — фильтр, направленный на борьбу с неестественно быстрой динамикой прироста ссылок.
Вот естественная динамика, характерная для Википедии:
(Картинка кликабельна)
А вот — для сайта, допустившего несколько резких приростов:
(Картинка кликабельна)
Без комментариев, как говорится.
Работает следующим образом: если за определённый, короткий период времени на сайт появилось количество ссылок, превосходящее предельный порог, то все ссылки, размещенные сверх него, не учитываются.
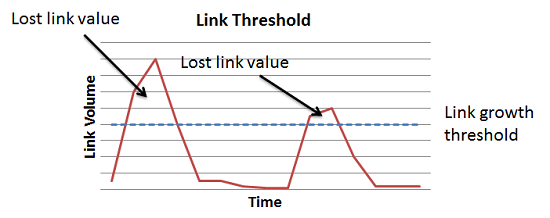
Разработчики поисковых алгоритмов предусмотрели ситуацию, когда естественная ссылочная динамика может нарушаться — это информационный повод. При появлении информационныой бомбы на неё резко начинают размещать ссылки, отличием от обычного лавинообразного платного размещения является большое количество ссылок с новостей.
Поэтому для оптимизаторов возможны варианты нивелирования последствий ссылочного взрыва, один из них — размещение дополнительных ссылок на новостных ресурсах. Таких ссылок должно быть много, ресурсы также должны быть посещаемыми.
Важно отметить, что ссылки из новостей должны индексироваться раньше, чем ссылки с большинства других внешних ресурсов.
Управление динамикой:
Используйте Webmaster Яндекса, выгружайте внешние ссылки и отслеживайте их прирост. Очень важно соблюдать постоянство наклона кривой прироста ссылок, она должна быть гладкой, без скачков.
Связанность ссылочной массы
Сайты, созданные для продажи ссылок на биржах, обычно практически не имеют внешней ссылочной массы.
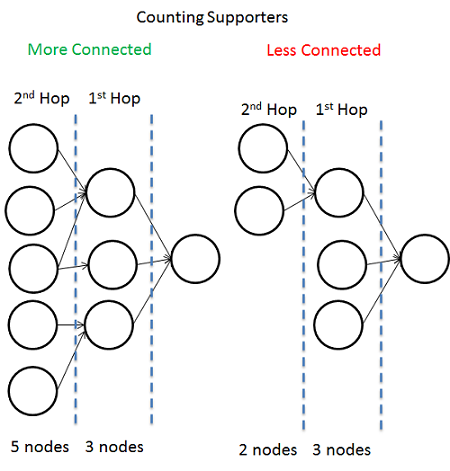
Не спам — слева, спам — справа.
Для поисковика нет особых проблем, в том числе и в плане дополнительных вычислительных мощностей, для вычисления подобных связей, поскольку это можно провести на этапе расчёта PageRank.
Для выбора доноров нужно использовать сайты:
- имеющие большое количество внешних ссылок;
- имеющие общих доноров.
Разнообразие весовых показателей
В естественной ссылочной массе показатели ТИЦ и PR доноров разнообразны. Нет жестких рамок, например не бывает такого, чтобы все доноры обладали фиксированным PR или ТИЦ. Более того, маловероятна ситуация, когда все доноры попадают в узкие рамки, например PR 2-3, ТИЦ 10-50 и т.п.
Таким образом, для обеспечения естественности нельзя подбирать доноров по одному единственному фильтру. Более того, естественная ссылочная масса будет во всём диапазне значений выглядеть так:
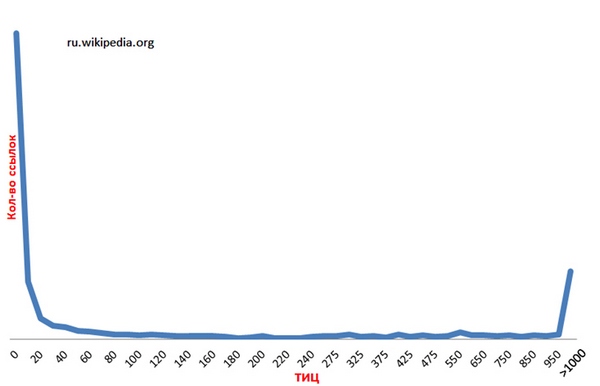
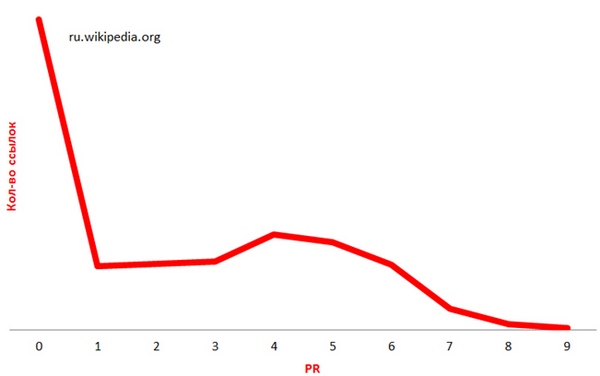
В естественной ссылочной массе большинство ссылок имеют нулевые показатели ТИЦ и PR. Скачок после на значении >1000 обусловлен тем, что значительное количество ссылок имеет очень высокие значения ТИЦ. Если эти значения раскрыть получим ровную прямую.
При наборе ссылочной массы:
- отдавать предпочтение донорам с разнообразным статическим весом;
- следить за распределением весовых показателей ссылок.
Соотношение анкорных и безанкорных ссылок
Поисковые системы также отслеживают соотношение между анкорными и безанкорными ссылками.
Свежий пример: Google Penguin.
Вообще использование безанкорных ссылок недооценено многими SEO оптимизаторами. Скорее всего это вызвано следующим: если у конкретного запроса позиции не дотягивают до ТОПа, то оптимизатор считает, что проблема в недостатке ссылок и начинает закупать ещё. Поскольку он продвигает конкретный запрос, то не возникает даже мысли о том, что причина может скрываться в других факторах. Анкорный вес быстро уходит в насыщение (считаем по BM25) и остаётся необходимость в наращивании только статического веса. Для этого нужны как раз безанкорые ссылки.
Более того, в «естественной среде» редко ссылаются с использованием анкора.
Стоит оговориться, безанкорными ссылками являются:
- ссылки без текста;
- название компании в анкоре;
- URL сайта в анкоре;
- URL страницы в анкоре.
Вот так выглядит естественное соотношение безанкорных и анкорных ссылок на примере Википедии:

А так соотношение для сайта под санкциями (Google Penguin):

Рекомендации:
- контролируйте количество вхождений анкора в анкор-листе, если позиции по запросу стоят на месте, возможно, причина в других факторах;
- проверяйте распределение статического веса в рамках сайта, при правильном распределении многие запросы выйдут в ТОП без использования их вхождений в анкор.
Длина анкора в словах
Кроме соотношения анкоров важна длина анкора в словах, она также используется как фактор для определения спамного ссылочного профиля (косвенно это подтверждает Мадридский доклад от Яндекса). Не спамные ссылочные профили содержат преимущественно однословные анкоры. Спамные — 2-х и 3-х словные.
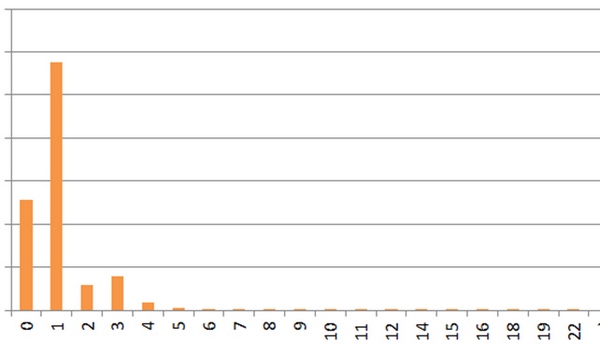
Википедия
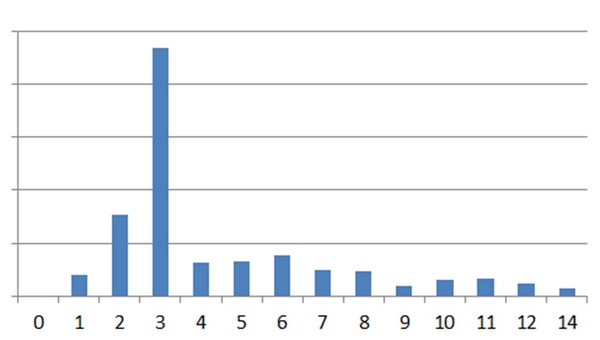
Спам
Для чистоты эксперимента в качестве естественного ссылочного профиля использовалась Википедия, в качестве спамного — другой сайт, название которого также состояло из одного слова и одновременно могло использоваться как на кириллице, так и на латинице.
Длина анкора в символах
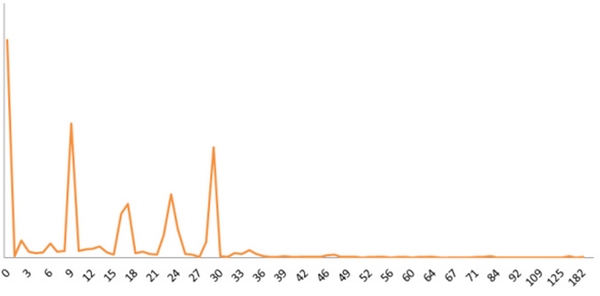
Не спамный ссылочный профиль
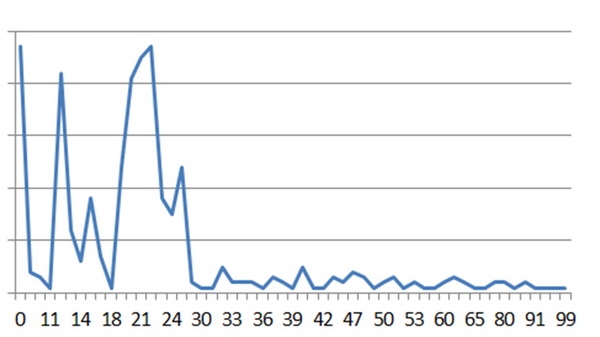
Ссылочный профиль сайта, продвигающегося через Sape
Интересно то, что для сайтов, продвигающихся через Sape или через агрегаторы, длина анкора лимитирована на 100 символах (значение было проверено экспериментально на 15 сайтах). Для естественного ссылочного профиля она не лимитирована.
Рекомендации:
- не размещайте все ссылки через биржи;
- используйте длинные анкоры.
Коммерческие ссылки
В заключении статьи напомню о Мадридском докладе Яндекса, который был опубликован ещё в 2009 году, но до сих пор его тезисы игнорируются большинством SEO специалистов.
Рассмотрим основные моменты.
Алгоритм позволяет с высокой точностью (95%) выявить сайты продающие и покупающие ссылки.
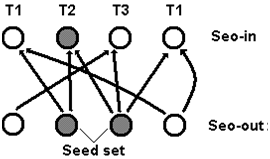
Принцип действия основан на алгоритме HITTS.
1. Вводятся классификаторы:
- SEO-Text — степень оптимизированности текста ссылки;
- SEO-Topic — тематики, наиболее характерные для продвигаемых сайтов (в оригинальном алгоритме указано 22 тематики);
- SEO-out — вероятность того, что сайт торгует ссылками;
- SEO-in — вероятность того, что сайт продвигается с использованием покупных ссылок;
- SEO-link — вероятность того, что ссылка платная.
2. Расчёт вероятности того, что сайт торгует ссылками:
SEOout = k1×AvgSEOin + k2×AvgSEOtext + k3×NTh + ...
AvgSEOin — среднее значение количества ссылок с данного сайта
AvgSEOtext — среднее значение SEO текстов этих ссылок
NTh — количество тематик
3. Расчёт вероятности того, что ссылка платная:
SEOlink = l1×SEOtext + l2×SEOin + l3×SEOout + ...
Ki и Li — коэффициенты, подбираются на основе обучающей выборнки.
Таким образом:
- те документы, которые ссылаются на множество документов различных тематик, вероятно могут продавать ссылки;
- те документы, которые получают множество таких ссылок, вероятно, покупают ссылки.
Отдельного внимания заслуживает тот факт, что ссылка, определяемая как коммерческая по показателю SEO Text, может даже не содержать слов «купить», «продажа» и т.п. Она определяется по общим показателям текста ссылки.
Кроме того, поскольку учитывается тематика продвигаемого сайта, становится невозможным (или очень сложным) продвижение сайтов некоммерческих тематик с использованием арендных ссылок.
Заключение
В какой-то момент SEO стало синонимом слова спам, сейчас, поисковые механизмы стремятся к сокращению спамных методов продвижения сайтов. Большинство из них уже стали невозможными.
И, знаете, в этом нет ничего плохого: с ростом качества алгоритмов антиспама растёт, SEO специалистам уже приходится применять ряд средств используемых маркетологами, тем самым повышая качество продвигаемых сайтов в целом.

 Теги:
Теги:














