
Основные зарубежные поисковые системы, их доля на рынке
 Львиная доля всего мирового поиска приходится на такие поисковые системы: Google Search, Yahoo! Search и Microsoft Live Search. Эти три американские компании конкурируют между собой в борьбе за главный приз, то есть пользователей, которые пришли за помощью в Интернет.
Львиная доля всего мирового поиска приходится на такие поисковые системы: Google Search, Yahoo! Search и Microsoft Live Search. Эти три американские компании конкурируют между собой в борьбе за главный приз, то есть пользователей, которые пришли за помощью в Интернет.
Чтобы оценить доли присутствия этих и других компаний было бы неплохо, если бы поисковые системы сами давали подробные отчеты о своей работе в свободный доступ, однако это маловероятно, так как подобная информация является коммерческой тайной.
Но все-таки существуют компании, которые как раз и занимаются сбором статистики по подобным вопросам. Наиболее авторитетной в этом плане является компания NetRatings, Inc. Именно она постоянно информирует Интернет-сообщество о результатах своих исследований в областях интернет-коммерции, маркетинга, онлайн рекламы и поисковых технологий.
По данным последнего опубликованного отчета об объемах поисковых запросов за декабрь 2006 года, на американском рынке мы можем наблюдать такую ситуацию рис.1.
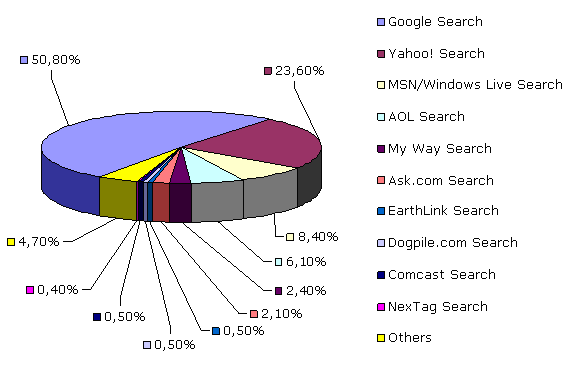
Судя по этой статистике, сейчас более 80% американского рынка поиска делят между собой те самые три компании, о которых мы говорили ранее.
Google Search
На сегодняшний день компания Google Inc. владеет самой популярной поисковой системой, Google имеет одну из самых больших баз проиндексированных документов. Движок поисковой системы разработали еще в 1997 году Сергей Брин и Ларри Пейдж, выпускники Стэндфордского университета. Они же одними из первых применили для алгоритмов определения релевантности страниц технологию PageRank, которая основывается на авторитетности документа, в зависимости от внешних ссылок на него.
Поначалу компания Google позиционировала себя только на рынке поиска. Сейчас же она имеет множество направлений и различных интернет-сервисов, среди которых разработка программного обеспечения, бесплатная почтовая система, собственная система электронных платежей и другие.
Yahoo! Search
Изначально, с 1995 года, портал Yahoo! существовал исключительно как каталог сайтов. Со временем Yahoo! обрастала все новыми и новыми сервисами и мини-проектами, а где-то с 2000 года стала использовать поисковый движок сторонней компании Inktomi. Чуть позже выбор пал на поисковый движок Google. Именно его и использовала компания Yahoo! до 2004 года. А в 2004 году была представлена собственная поисковая система, и от услуг Google пришлось отказаться.
Что удивительно, в 2002 году президент компании Yahoo Терри Семел (Terry Semel) вел переговоры о покупке Google Inc, которой было предложено $3 млрд., но владельцы хотели за свою компанию $5 млрд. На то время эта сумма для Yahoo была просто астрономической, так как пришлось бы задействовать все свои резервы.
Через 2 года компания Google вышла на биржу и ее рыночная капитализация превысила $150 млрд. Сейчас Google занимает 2 место среди IT-компаний в мире по рыночной капитализации. На первом месте находится компания Microsoft.
MSN / Windows Live Search
Учитывая то, что компания Microsoft – мировой лидер среди компаний по рыночной капитализации, и то, что более 2/3 компьютеров в мире работают под ее операционной системой, было бы наивно думать, что Microsoft не поборется за рынок поисковых технологий. Так и есть, компания давно хотела разработать свой поисковый движок и сейчас он у нее уже есть. Пусть он не так популярен, как Google, но предпосылки для развития и улучшения качества поиска у него есть. А именно качество поиска привлекает к себе как пользователей, так и потенциальных рекламодателей.
Особенности продвижения сайтов в поисковых системах Google, Yahoo, Live. Разбор алгоритмов борьбы с поисковым спамом, песочница Google, Supplemental Results, бонусы и фильтры, мифы и реальность
Основные принципы ранжирования документов у популярных поисковых систем практически одинаковы. Но некоторые нюансы работы, методы определения поискового спама и отношение к нему все же несколько отличаются.
Рассмотрим наиболее интересные моменты каждой поисковой системы.
Google Search
На сегодняшний день это самая популярная поисковая система. Она имеет наибольшее количество запросов пользователей в месяц. Также считается, что именно поиск Google сейчас обладает самой продвинутой системой. Вследствие такой популярности возникли и очень высокие требования к качеству поиска, и их пока компания выполняет на высоте.
Изо дня в день мы слышим о новых и новых патентах, которые Google регистрирует в области поисковых технологий. Вебмастера всего мира пытаются разобраться, работают ли эти патенты уже сегодня или это вопрос ближайшего будущего. Не претендуя на самые полные знания в этой области, могу рассказать вам об наиболее важных практических моментах, возникающих при продвижении сайта.
Отношение к контенту сайта
Эта поисковая система очень требовательна к уникальности текста на вашем сайте. Современные алгоритмы сегодня позволяют определять уникальность текста по различным признакам. Определить точную копию документа очень легко. Если вы, например, сделали страницу, содержащую абзацы из других источников – будьте уверены Google об этом знает. Другой вопрос, как он отреагирует. Качество поиска оценивается в конечном итоге тем, нашел ли пользователь то, что искал или нет.
Если говорить о дублировании контента, то это очень серьезная задача для любой поисковой системы, правильно определять это. Если вы написали интересную статью и разместили ее на разных проектах, то Google при одних и тех же условиях будет выдавать выше более авторитетные, по его мнению, ресурсы, а не более свежие или ранее напечатанные материалы. Большую роль здесь играет PageRank.
К контенту, который напичкан ключевыми словами, отношение довольно обычное. На результаты поиска все эти проценты плотности после какого-то предела не влияют вообще, а вот быть распознанным как спам документ имеет все шансы.
По заявлению разработчиков, Google имеет несколько кешей для хранения информации, которые могут выполнять несколько различные функции друг от друга. Например, есть так называемый новостной кеш. В него попадают часто обновляемые документы или просто свежие документы на некоторое время. Есть основной кеш, в котором хранится информация о текущем состоянии веб страниц. Также, возможно, есть кеш, где хранятся все изменения документов и история их развития. Как точно это реализовано, трудно сказать, но информацию о каком-то количестве изменений каждого документа Google хранит.
Основываясь на информации, которая есть у Google, в определенные моменты времени в основной поиск подмешиваются сайты с новостного индекса с более высокими статическими коэффициентами, далее со временем они либо опускаются вниз, либо в результате работы каких-то алгоритмов могут вообще пропадать.
Также у Google есть дополнительный индекс, так называемые Supplemental Results. Туда, по заявлениям разработчиков, могут попадать как нечеткие дубликаты страниц, документы с «плохим» контентом, а также просто страницы с невысоким значением PageRank. Далее при ранжировании документов эти страницы могут не участвовать в основном поиске, но если попробовать поискать по очень редким запросам такие страницы, то мы их сможем увидеть. Судя по всему, Google просто обнуляет им какие-то параметры, которых не хватает для основного поиска.
Что делать, если страницы вашего сайта попали в Supplemental Results? Убедитесь в том, что каждая отдельно взятая страница имеет уникальное внутреннее наполнение, отличное от других страниц этого же сайта, уникальное содержание тегов < title > и META-description. Если все это есть, то позаботьтесь о внешних ссылках на эти страницы. Также нужно немного набраться терпения и подождать. Если все условия выполнены, то будьте уверены, что скоро ваши страницы появятся в основном индексе.
Отношение к внешним ссылкам на сайт
Старайтесь, чтобы абсолютно каждая ссылка, ведущая на ваш сайт была с уникальным текстом. Существуют алгоритмы, которые фильтруют ссылки с одинаковым текстом. Для вас это будет означать, что ваш труд не принесет никакой пользы.
Также нужно иметь ввиду, что обратные ссылки должны расти медленно, в соответствии с ростом контента. Это означает, что очень быстрое увеличение количества ссылок на ваш сайт приведет к тому, что сайт получит какой-то штраф и надолго потеряет возможность конкурировать с остальными.
Чем дольше стоит ссылка с определенным ключевым словом, тем больше пользы от нее. Частая смена текстов ссылки на одной и той же странице сведет силу этой ссылки к минимуму. Все эти моменты отображены в патентах Google.
Очень важную роль играет PageRank страницы, с которой ведет ссылка на ваш сайт. Чем он выше, тем лучше. Но стоит учесть, что Google легко определяет тематику как ссылающихся сайтов, так и тех, на кого ссылаются. И очень часто бывает, что ссылка, ведущая с сайта с высоким PageRank, практически ничего не добавляет, так как ведет на нетематический ресурс.
Борьба с поисковым спамом
Нам нужно смириться с тем, что очень большая часть Интернета – это информационный мусор, или шум. Если человек сразу может по внешнему виду определить, что это за сайт, то поисковые системы должны делать это максимально автоматизировано.
Сейчас Google легко определяет клоакинг, чрезмерное использование ключевых слов в тексте, исполняет простенькие JavaScript-ы и ищет редиректы. Также на сегодняшний день у этой поисковой системы довольно хороший алгоритм определения дубликатов.
Вычислительные процессы, происходящие внутри этой сложной системы, независимы и могут быть разбросаны во времени. Я имею в виду, что так называемые выбросы данных могут происходить по разным параметрам в разное время. Например, если вы поменяли Title на сайте, то увидеть, как это повлияет на поиск, можно уже через несколько дней, если поменяли полностью контент, то должны дождаться другого мини-апдейта. Сила обратных ссылок пересчитывается, например, раз в месяц. PageRank пересчитывается постоянно. Но на разных датацентрах и при разных условиях выбросы данных в основной поиск могут не совпасть с пересчетом других параметров. Поисковым спамерам не подходят такие варианты – они хотят все и сразу, вот и попадаются за массовость и скорость на крючки различных алгоритмов. Определение спама в Google полностью автоматизировано, модераторы стараются не вмешиваться в работу алгоритмов и удалять сайт руками – это делается алгоритмически. В этой борьбе всегда выигрывает тот, кто не спешит и последовательно движется к своей цели.
Что такое «песочница», или Google Sandbox
Пожалуй, это самый жаркий момент, который интересует вебмастеров всего мира в Google. Вследствие различных совершенствований алгоритмов сложилась такая ситуация, что новому сайту практически невозможно попасть на первую страницу поиска в Google по конкурентным запросам. Есть мнение, что поисковая система просто не пускает в течение шести месяцев новые сайты в выдачу по конкурентным запросам. Это немного не так, и сейчас я попробую вам объяснить почему.
Первое, на что нужно обратить внимание – это на публикации представителей этой поисковой системы. Они заявляют, что ничего подобного специально не разрабатывали, и все это следствие различных факторов. Они не могут быть одинаковыми для всех сайтов, а рассчитываются в зависимости от ситуации.
Основная идея этого явления (Sandbox) заключается в том, что недавно появившийся в сети сайт не может быть авторитетным и его голос не стоит принимать во внимание. Для начала люди должны узнать все о нем, проанализировать, дать свое мнение. На все это нужно время чисто физически. Также немного неестественно выглядит сайт, который вдруг ни с того ни с сего получил много ссылок, а его конкуренты нет. В зависимости от ситуации Google рассчитывает пороговые значение для каждого сайта, также это явление зависит от поискового запроса. Пока сайт не удовлетворяет всем требованиям, его либо нельзя найти среди первых 1000 результатов, либо он очень далеко от первой страницы, если общее количество всех релевантных запросу документов небольшое.
Далее, мы более наглядно попробуем разобрать работу этой системы, пусть и обобщенно.
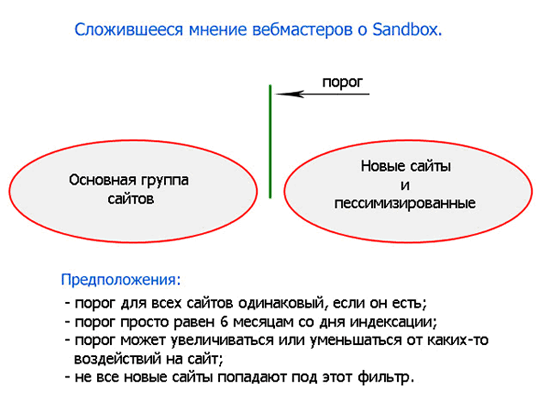
Судя по этому рисунку, многие вебмастера думают, что это какая-то дискриминация со стороны Google по отношению к их новым «чудо-сайтам». Многие возмущаются: «Как же так, у меня ведь такой интересный сайт»? Почти все сводится к каким-то санкциям и запретам, но техническую сторону вопроса никто даже не собирается рассматривать. В любом случае, для большинства «Sandbox» выглядит как черный ящик. На выходе имеем какие-то данные, и на входе. Но связать их в одно целое, выяснив взаимодействие факторов четко, не удается. Каждый вебмастер или специалист по продвижению сайтов пытается трактовать этот «черный ящик» по-своему. Вследствие чего появляется большое количество фантастических рассказов и рецептов, чтобы побороть это явление. Некоторые пишут на форумах, что “Я разгадал секрет песочницы, заходите ко мне в закрытый платный раздел – но не думайте, что я вам стану все рассказывать”. Это выглядит очень смешно, учитывая огромные интеллектуальные и технические возможности специалистов из Google. Надеяться на какие-то прямолинейные рецепты, которые сработают для любого случая, просто глупо.
Давайте хотя бы попытаемся предположить, что же может входить в эти грандиозные формулы Google, какие факторы и в какой степени на что влияют.
Начнем с временных факторов. Нам известно, что компания Google уже зарегистрировала несколько патентов на тему ранжирования сайтов, полагаясь на исторические данные об их развитии. Теперь для определения релевантности в алгоритмах могут использоваться дата регистрации домена, дата первой индексации сайта, даты появления внешних ссылок и их динамика, даты всех изменений текста на сайте и другие.
Внимательно прочитав все эти патенты, можно предположить, что:
- чем раньше сайт зарегистрирован – тем лучше;
- чем раньше первый раз проиндексирован – тем лучше;
- чем дольше стоят внешние ссылки на сайт, тем больше веса они передают;
- если внешние ссылки появляются естественно, не очень быстро, то это хорошо;
- если сайт часто обновляется, то это хорошо;
- если сайт резко поменял свою тематику через какое-то время, то это плохо;
- со временем усиливается влияние всех факторов как внутренних, так и внешних.
Поскольку поисковые системы ранжируют страницы сайтов, то можно предположить, что есть какие-то факторы, зависящие от самого сайта. Это могут быть все те временные факторы, что мы упомянули, а также внутреннее содержимое сайта. Можно предположить, что Google ведет статистику по всем сайтам в сети и знает, какой вид имеет среднестатистический хороший сайт, как он должен развиваться, в какой последовательности. Тогда можно сказать, что лучше не усердствовать с оптимизацией контента сайта на начальном этапе развития, не гнаться за плотностью ключевых слов и прочим.
Безусловно, что на работу этого алгоритма влияют внешние факторы, применительно к какому-то конкретному сайту. Какими же они могут быть? Естественно, что речь идет о ссылках. Все внешние ссылки, текст, которым они ссылаются – все это может влиять на расчет того порога в «Sandbox». Учитывается как количество ссылок, динамика их появления, так и то, с каких сайтов эти ссылки стоят, с какими именно ключевыми словами. Появление за короткий промежуток времени большого количества внешних ссылок – это плохо. Ссылки с плохих сайтов – это не плюс. Ссылки с одинаковым текстом, участие в системах автоматического обмена и кольцах – это плохо. Естественные ссылки и ссылки с авторитетных сайтов – это хорошо.
Что же еще может участвовать в алгоритмах этого «Sandbox». Как для меня, так это абсолютно очевидно – это запрос, который вы вводите в поисковой системе. Именно от запроса будет, в большей мере, зависеть то, будет ли ваш сайт участвовать в основной группе сайтов или попадет под воздействие ограничительного алгоритма Sandbox.
Давайте разберемся, какими же свойствами вообще обладает поисковый запрос. Каждый запрос имеет частоту его поиска в системе. Есть запросы с большой популярностью, у них эта характеристика больше. А есть и запросы с маленькой частотой набора. Когда происходит выборка в индексе по каким-то словосочетаниям, то появляется определенное количество всех релевантных документов. Появляется количество всех ссылок в сети с этими ключами, и Google известны все их числовые характеристики.
Также, зная запрос, можно узнать, покупают ли рекламодатели объявления в Google Adwords или нет, какая там общая конкуренция. Имея такую статистику по частоте, конкуренции, суммам, которые тратятся, Google может произвести группировку сайтов по принципу: коммерческий или нет. И в зависимости от этого настроить автоматически коэффициенты, участвующие в расчетах алгоритма «Sandbox».
Представители Google как-то сообщали о том, что более популярным запросам уделяется больше внимания, чем непопулярным в плане контроля качества. Естественно, что все это делается автоматически, то есть на анализ популярных тематик тратится больше процессорного времени всех серверов. По очень популярным, коммерчески привлекательным, запросам мы почти не будем замечать плохих сайтов или дорвеев, тогда как по запрещенным в Adwords тематикам или просто редко набираемым запросам мы можем увидеть до 90% дорвеев на первой странице. Все это связанно с тем, что более сложные алгоритмы вступают в работу только при определенных частотах, и нет смысла тратить дополнительные ресурсы на пересчет всех параметров. Там, где это неоправданно, некоторые алгоритмы не работают. Ведь качество поиска определяется чем? Да просто, доволен ли пользователь тем, что ему предлагается по запросу или нет. Если он искал что-то, нашел и остался довольным, то поиск качественный.
Также во всей этой системе участвует и сам пользователь. То, из какой страны он подает запрос, каким региональным Google пользуется, может сказаться на результатах ранжирования. Но это влияние, в частности, будет зависеть от тех же частотных характеристик поискового запроса, только в контексте сложившихся региональных особенностей.
Учитывая все ранее сказанное, можно предложить другую обобщенную схему «Sandbox».
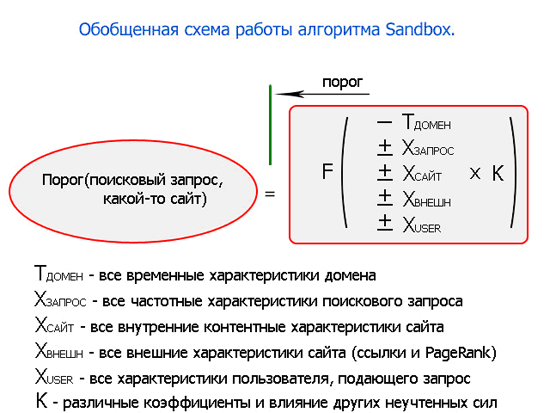
Ну вот, когда рассмотрено большинство возможных факторов, можно сделать какие-то выводы, примерить на эту схему то, с чем мы сталкиваемся в реальности, и проверить работают ли наши предположения.
Временные характеристики домена однозначно только уменьшают пороговое значение. Но есть взаимодействие между датой регистрации домена, датой первой индексации, датами появления обратных ссылок. Если просто зарегистрировать домен и отложить его на время, не делая сайт и не ставя внешние ссылки, то это минимально повлияет на пороговое значение. Более важной составляющей является дата первой индексации и даты появления, динамика роста внешних ссылок.
Чем популярнее запрос, тем больше коэффициенты для расчета порогового значения. Также учитывается коммерческая сторона поискового запроса и тематика.
Внутренние контентные характеристики сайта минимально влияют на процесс расчета порога, но излишнее количество ключевых слов (переоптимизация сайта) ведет к его увеличению.
Внешние характеристики сайта могут как уменьшить время пребывания под этим фильтром, так и увеличить.. Если не выходить за пределы «золотой середины» в обе стороны, то это, как минимум, не увеличит порог. Какие именно коэффициенты этого взаимодействия, сколько ссылок надо ставить, с какой скоростью, с каких сайтов и с каким PageRank – все это точно сказать невозможно. Эти параметры рассчитываются динамически под каждый конкретный запрос и сайт. Например, не нужно ставить на новый сайт ссылки с таких же новых сайтов, а также не нужно сразу ставить ссылки с PageRank=8, например.
В зависимости от того, какой пользователь подает запрос, в какой региональный Google, результаты выдачи могут отличаться. Как объяснить, например, то, что для русских запросов этот фильтр либо вообще не наблюдается, либо только по самым конкурентным тематикам? Да очень просто. Популярность этих запросов в Google не так велика, как вы думаете. Люди мало пользуются этой поисковой системой, частотные характеристики запросов меньше, чем англоязычных, вот и алгоритмы чуть мягче. Все это из-за конкурентности запросов и не надо думать, что под каждый язык пишутся свои какие-то особенные алгоритмы. Поисковая система оперирует словами, фразами на разных языках. Для каждого языка есть свои особенности, но это мало влияет на чисто технические задачи – поиск по базе данных и расчет всяких математических формул.
Yahoo Search
Это вторая по популярности поисковая система в мире. Компания Yahoo имеет большую предысторию к собственному поисковому движку и возможности. Как показывает история, это стабильный представитель второго места. Учитывая то, что компания занимается не только поиском, то быть вторым по поиску и первым в других областях не так уж и плохо.
Отношение к контенту сайта
По аналогии с Google, данная поисковая система без труда определяет клоакинг, редиректы и напичканные ключевыми словами страницы. Небольшое отличие в том, что увеличение плотности ключевых слов ведет к увеличению позиций в Yahoo. Допустимые пределы у этой поисковой системы где-то в 2 раза выше, чем у Google. Но если в Google надо очень постараться, чтобы сайт полностью за это забанили, то в ситуации с Yahoo разговор будет коротким – бан всего сайта, а в некоторых случаях и ip адреса.
Отношение к дублированному контенту, естественное, – это плохо. Но вот реализация алгоритмов немного другая. Если в Google вы в большинстве случаев не сможете за это получить бан, то в Yahoo – это абсолютно реально, и надо будет еще доказать, кто прав. Но сами алгоритмы определения дубликатов смотрятся немного несовременно – очень много времени проходит на определение. Возможно, это связанно с сезонными апдейтами Yahoo. Почти все параметры, такие как вес обратных ссылок и других факторов пересчитываются и выбрасываются в основной поиск раз в 3 месяца. Текстовые, внутристраничные, факторы обновляются намного чаще, но там, где их влияние не столь решающее, мы не будем видеть никаких изменений в выдаче до сезонного апдейта.
Еще одна небольшая особенность – Yahoo учитывает содержимое мета-тега description. Его важность очень маленькая, но все же сейчас он учитывается. Возможно, в будущем этот дефект будет устранен.
Отношение к внешним ссылкам на сайт
В отличие от Google, Yahoo не так критична к одинаковым текстам ссылок на ваш сайт. Но если Google умеет распознавать синонимы, падежи, сокращения, то здесь вам нужно стараться ставить ссылки с точным вхождением слов, которые есть на сайте.
За массовый искусственный рост обратных ссылок, за участие в системах автоматического обмена ссылками можно получить бан. Вы можете также быть исключены из индекса просто за то, что другие сайты нарушали лицензию на поиск, а вы просто на них ссылались, или ваш сайт размещен на том же ip адресе.
Какой-либо эффект от простановки тех или иных ссылок можно наблюдать не так часто, как хотелось бы. Апдейты в Yahoo происходят гораздо реже, чем у других поисковых систем.
Борьба с поисковым спамом
Нельзя сказать, что Yahoo не борется с поисковым спамом, но если сравнивать с Google, то может показаться, что их попытки не настолько успешны. Опять же, повторюсь, возможно, это связано с очень редкими апдейтами. Очень радует служба поддержки Yahoo. Если вы вдруг увидите какие-то сомнительные сайты в выдаче, сообщаете им, и очень оперативно эти сайты пропадают. Да, но вот только в Google этих сайтов вы можете никогда и не увидеть – они, как говорится, «погибают на подлете».
Microsoft Live
По современным меркам – это довольно новая поисковая система и у нее еще все впереди, учитывая то, какими возможностями обладает компания Microsoft.
Среди тройки лидеров поисковых систем Microsoft Live выглядит немного не готовой к современным реалиям и требованиям к качеству поиска. Со временем, думаю, эта ситуация немного улучшится.
Отношение к контенту сайта
Пожалуй, в этой поисковой системе внутреннее наполнение сайта как нигде больше имеет влияние на релевантность и позиции в выдаче. Здесь очень важна плотность ключевых слов, и чем больше, тем лучше. Но есть тоже некий порог. Учитывая то, что сейчас у Live самые частые апдейты и мы можем наблюдать все изменения текста и их влияние на выдачу практически каждую неделю, то говорить о каких-то экзотических алгоритмах пока рано. Здесь пока нет таких понятий, как новый сайт, старость сайта – все сайты ранжируются одинаково.
Отношение к внешним ссылкам на сайт
На данный момент рано говорить о каких-то устоявшихся алгоритмах в этом плане у Live. Разработчики постоянно что-то совершенствуют. Но уже четко просматривается то, что никаких фильтров на одинаковые ссылки и ссылки с одинаковых ip пока нет. Если хотите быть высоко в Live, просто ставьте ссылки с текстом, который точно есть на сайте в тексте и Title. За счет самых быстрых апдейтов ссылочной базы среди большой тройки поисковиков мы можем наблюдать результаты своего труда практически каждую неделю.
Борьба с поисковым спамом
Нельзя сказать, что компания Microsoft не ведет разработки в этом плане. Они есть, даже есть .
Например, они разрабатывают свою систему, которая будет искать поисковый спам во внешних факторах. Сотрудники исследовательского отдела тщательно анализируют мировые тенденции спама, смотрят, как борются с этим делом другие поисковые системы.
Думаю, в будущем все эти исследования принесут свои плоды: поисковым спамерам будет труднее влиять на результаты поиска этой системы, и, как следствие, – улучшится качество поиска.

 Теги:
Теги:


